2010年08月11日
■ 国会図書館の施策で全国の公共機関のWebサイトが消滅する 岡崎図書館事件(5)
平成22年4月1日施行の改正国立国会図書館法に基づき、国立国会図書館が、国・地方公共団体等の公共機関を対象に、インターネット上で公開されている資料のWebクローラによる収集を開始したという。その説明資料によると、クローラのアクセス間隔の基準は「1秒以上」だという。中野区立図書館の場合、/robots.txt が置かれておらず、セッションタイムアウトは実測で600秒*1であることから、1秒間隔でクローラが来ると*2、散発的につながらない状態がしばしば発生すると思われる。
目次
- /robots.txtで自ら姿を隠す公共図書館
- 国立国会図書館法第25条の3第2項に違反
- 国会図書館が公共機関のWebサイトを消滅させる虞れ
/robots.txtで自ら姿を隠す公共図書館
中野区立図書館や岡崎市立中央図書館は、三菱電機インフォメーションシステムズ(以下、三菱電機IS)の図書館システム「MELIL/CS」を採用しており、同じシステムを採用している全国の図書館の一覧が以下にある。
- 日本のソフト別OPACリスト #Melil
- ASP版MELIL/CS導入図書館リスト, サーバ管理者日誌, 2010年7月21日
「MELIL/CS」には旧型(ASPによる実装)と新型(ASP.NETによる実装)の2種類があり、URL中のファイル名の拡張子が「.asp」のものが旧型、「.aspx」が新型として見分けられる。
旧型「MELIL/CS」を採用している全国の図書館を見てまわると、半数以上のところで /.robots.txt を配備していることがわかる。中には、ルートディレクトリに置かなければ意味をなさないのに、サブディレクトリに置いているところもある。
どうしてこうバラバラなのか解せないが、それ以前に /robots.txt の設定内容も、ほとんどが以下の図1のような調子で、不必要な行が大量にあって異常なものになっている。/robots.txt の仕様をわからないままに書いているように見受けられる。
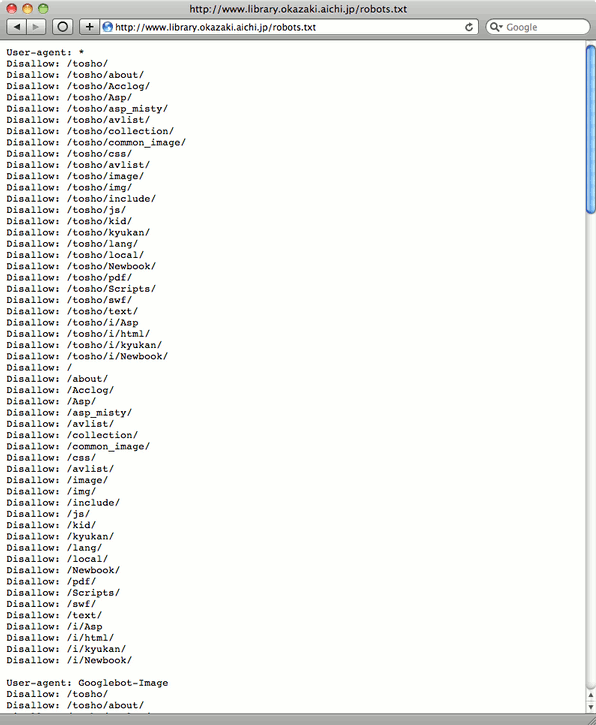
(2010年8月11日現在の岡崎市立中央図書館の /robots.txt より)
このように必死な感じで /robots.txt を配備するのは、そうしないと閲覧しづらくなる不具合が起きてしまうためなのだろうが、こんな設定(すべてのクローラに対して全ディレクトリ拒否)にしてしまうと、Web検索にも出て来なくなる危険がある。
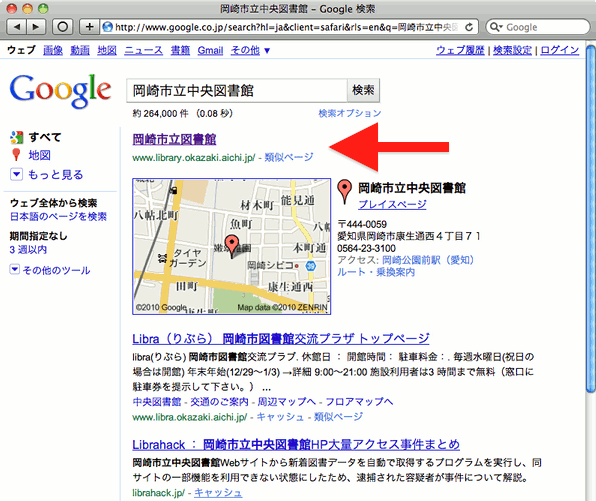
たとえば、「岡崎市立中央図書館」でGoogle検索すると、以下の図2の結果になる。図書館の正式名称は「岡崎市立中央図書館」なのに、検索結果には「岡崎市立図書館」と表示されている。トップページのタイトルは「Libra—岡崎市立中央図書館—」なのに、それが表示されていない。そして、通常ならば表示されるはずのページ概要も現れていない。
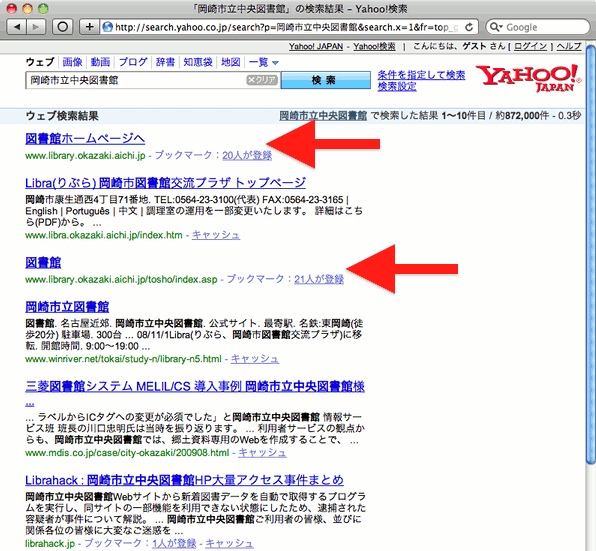
同様にYahoo!で検索してみると、次の図3のように、「図書館ホームページへ」、「図書館」などとタイトルが悲惨なことになっている。これは、「18歳未満」や「いいえ」で検索したときにYahoo!のトップページが出てくるように、リンク元の情報を基に検索結果が作られているためで、リンク元のタイトルが表示されているのであろう。図書館のWebサーバが全くクロールされていないために、こんな結果になっている。
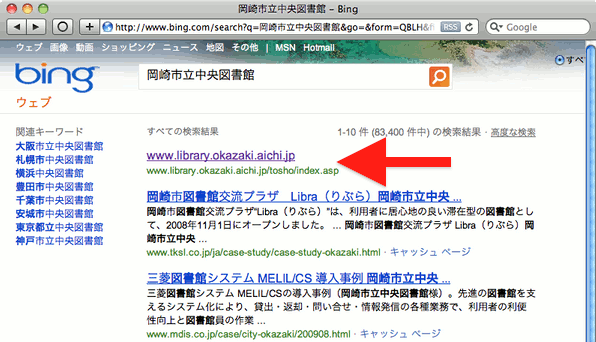
同様にbingで検索すると、以下の図4のように、タイトルすら現れない。SEO的に最悪な状況であるわけで、たまたま1番目に出ている状況だと思われる。
そして、同様にBaiduで検索すると、サイトが出てこない。Baiduではリンク元の情報を参考にしていないか、/robots.txt で拒否されているサイトは検索結果に出さない方針なのかもしれない。
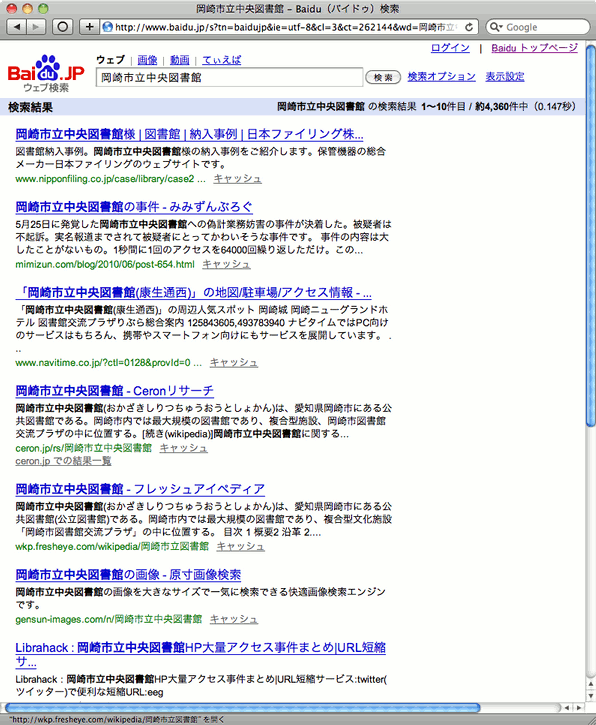
これは、「MELIL/CS」の /robots.txt を置いている他の図書館も同様で、たとえば、相模原市立図書館を検索すると、次のようになる。
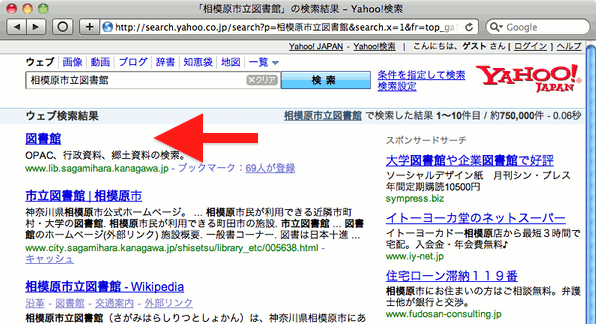
相模原市立図書館は、URLに「.aspx」とあるように、新型の方の「MELIL/CS」を採用しているので、もはや /robots.txt は不要なはず*3だが、旧型同様の /robots.txt が置かれている。
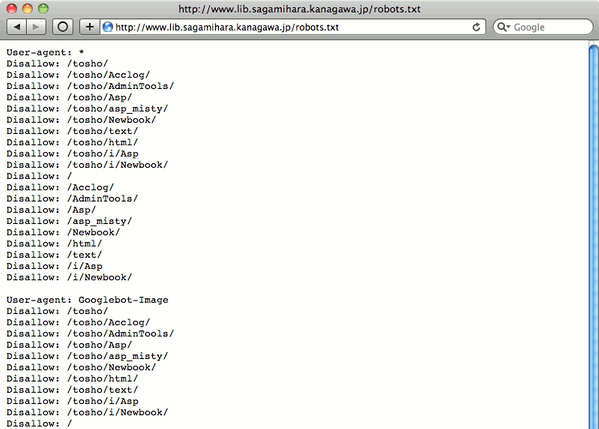
旧型から新型に切り替えられた際に放置されたためかもしれないが、そもそも、このような /robots.txt は消す必要があることに、図書館員も三菱電機ISも気づいていないのではないか。*4
国立国会図書館法第25条の3第2項に違反
昨年改正されて今年4月1日に施行された国立国会図書館法は、第25条の3において、次のように規定している。
第十一章の二 国、地方公共団体、独立行政法人等のインターネット資料の記録
第二十五条の三 館長は、公用に供するため、第二十四条及び第二十四条の二に規定する者が公衆に利用可能とし、又は当該者がインターネットを通じて提供する役務により公衆に利用可能とされたインターネット資料(電子的方法、磁気的方法その他の人の知覚によつては認識することができない方法により記録された文字、映像、音又はプログラムであつて、インターネットを通じて公衆に利用可能とされたものをいう。以下同じ。)を国立国会図書館の使用に係る記録媒体に記録することにより収集することができる。
2 第二十四条及び第二十四条の二に規定する者は、自らが公衆に利用可能とし、又は自らがインターネットを通じて提供する役務により公衆に利用可能とされているインターネット資料(その性質及び公衆に利用可能とされた目的にかんがみ、前項の目的の達成に支障がないと認められるものとして館長の定めるものを除く。次項において同じ。)について、館長の定めるところにより、館長が前項の記録を適切に行うために必要な手段を講じなければならない。
3 (略)
「館長が前項の記録を適切に行うために必要な手段」とは何かというと、「国立国会図書館法によるインターネット資料の記録に関する規程」第2条で次のように規定されている。
(インターネット資料の記録を適切に行うために講ずべき手段)
第二条 法第二十五条の三第二項の規定により法第二十四条及び第二十四条の二に規定する者が講じなければならない手段は、同項のインターネット資料を公衆に利用可能としている電子計算機において、館長の定める基準により、法第二十五条の三第一項の記録を行うために必要な情報を加え、又は同項の記録を妨げる情報を削ることとする。ただし、当該者が当該電子計算機について当該手段を講ずる権限を有しない場合は、この限りでない。
「館長の定める基準」とは、平成22年国立国会図書館告示第一号「国立国会図書館法第二十五条の三第三項のインターネット資料等に関する件」に書かれていて、
(国立国会図書館法によるインターネット資料の記録に関する規程第二条の基準)
2 国立国会図書館法によるインターネット資料の記録に関する規程(平成二十一年国立国会図書館規程第五号)第二条の基準は、国立国会図書館の館長が自動収集プログラムにより法第二十五条の三第一項の記録を行うことができることとする。
とある。要するにこれらは、/robots.txt を次のように設定せよという話である。

国立国会図書館は、改正国立国会図書館法に基づいたインターネット資料の収集を開始しており、以下のサイトで、「公的機関の皆様へ」として、この法で定められた義務について周知している。
- 資料収集・保存:インターネット資料の収集, 国立国会図書館
4) 収集にあたってのお願い
国立国会図書館法第25条の3第2項及び第3項に定めるとおり、下記のご対応をお願いいたします。
- 当館のインターネット自動収集に関して排除指定を行っている場合、その設定の変更・解除
変更方法については、説明用パンフレット(PDF:394KB)をご覧ください。
- (略)
- 当館のインターネット自動収集に関して排除指定を行っている場合、その設定の変更・解除
つまり、三菱電機ISの図書館システム「MELIL/CS」(旧型)を導入した多くの公共図書館は、Web検索から姿を隠したというだけでなく、国立国会図書館法第25条の3第2項に違反し、違法状態になっている。*5
図書館員や図書館システム業者がこのことに未だ気づいていないというのは、驚きを禁じ得ない。
表1で「設定あり」とした各図書館に加え、新型の「MELIL/CS」を導入している以下の公共図書館も、/robots.txt によってすべてのクローラに対して図書館の全ディレクトリを拒否している。(2010年8月11日現在)
- http://library.town.kuriyama.hokkaido.jp/robots.txt, 栗山町図書館, 北海道
- http://lib.city.iwamizawa.hokkaido.jp/robots.txt, 岩見沢市立図書館, 北海道
- http://www.library.city.suginami.tokyo.jp/robots.txt, 杉並区立図書館, 東京都
- http://www.lib.sagamihara.kanagawa.jp/robots.txt, 相模原市立図書館, 神奈川県
- http://www1.city.kawachinagano.osaka.jp/robots.txt, 河内長野市立図書館, 大阪府
- http://munakata.uxt.cknet.co.jp/robots.txt, 宗像市民図書館, 福岡県
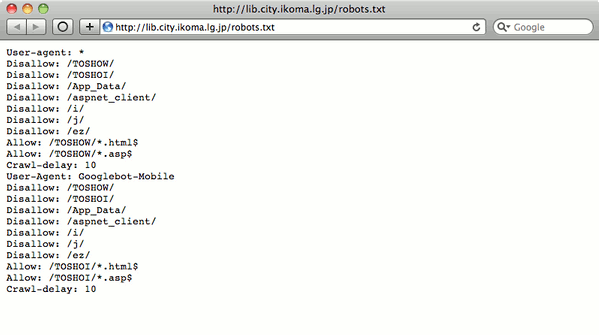
一方、生駒市図書館など、図9のように「Allow」の設定がなされていて、どうにかしようとしている様子のあるところもあるし、奈良市立図書館の /robots.txt のように、公開すべきディレクトリが除外されている*6ところも少なからずある。
国会図書館が公共機関のWebサイトを消滅させる虞れ
というわけで、国会図書館の周知が足りていないのではないか。もっと強行に、文部科学省から全国の図書館に通達を出すとか、総務省自治行政局から全国の自治体に通達を出すとか、そういったことは行われていないのだろうか。
ところで、そういった周知徹底をするならば、図8で引用した、国会図書館の説明用パンフレット「改正国立国会図書館法によるインターネット資料の収集について」の「ロボット排除について」の説明は、このままではマズいと思われる。

「下記のとおり変更してください」とあるので、意味もわからず切羽詰まって対応する係員が、このとおりに設定してしまう虞れがあるように思う。
つまり、元々どのクローラも拒否していなかったサイトが、新たに /robots.txt を作って、図の通りに「ndl-japan」のクローラだけ許可して、それ以外を全部拒否する設定(図中の「User-agent:* Disallow:/」の部分)を書いてしまう事態が起きる可能性が十分にあるように思える。
ざっくり探してみたところ、大阪医科大学の /robots.txt がちょっと怪しい。「User-agent: * Disallow: /」で全拒否した後、特定の検索エンジンのクローラだけ許可している。これでは一部の検索サイトでヒットしなくなるだろう。

このまま国会図書館の説明用パンフレットで周知徹底がされていくと、全国の公共機関が次々とWeb検索から姿を消していくかもしれない。
追記(24日)
8月24日13時00分の時点で、表1で旧型MELIL/CS導入の「設定あり」とした図書館のうち、観音寺市立図書館が /robots.txt を削除した以外、他はすべて /robots.txt で全クローラを拒否した状態を継続中であることを確認。同様に、新型MELIL/CSについて挙げた6つの図書館のうち、河内長野市立図書館が /robots.txt を削除した以外、他はすべて /robots.txt で全クローラを拒否した状態を継続中。
追記(31日)
8月31日9時55分の時点で、上記の /robots.txt の状況に変化なし。
追記(9月7日)
9月7日23時00分の時点で、加賀市立図書館の /robots.txt が消えたことを確認。他は(9月11日訂正削除)全クローラ拒否を継続中。
訂正(9月11日)
加賀市立図書館の表1のURLが誤っていた。「/robots.txt」としなければならないところを誤って「/toshow/robots.txt」としていた。このリンク先を閲覧して修正状況を確認していたため、上記「追記(9月7日)」で「加賀市立図書館の /robots.txt が消えた」としたのは誤りで、消えたのは「/toshow/robots.txt」であった。現時点では「/robots.txt」が存在しており、全クローラを拒否した状態になっている。(これが、以前からそうだたかは今となっては不明。)
追記(9月11日)
9月10日16時ごろ、岡崎市立中央図書館の /robots.txt が以下の内容に修正された。
User-agent: * Disallow: Crawl-delay: 1
「Crawl-delay: 1」の指定は意味がないと思う。
その他の図書館は、9月11日12時00分時点で変化なし。
追記(9月14日)
9月14日12時00分の時点で、加賀市立図書館と可児市立図書館の /robots.txt が修正された(上記の岡崎市立中央図書館と同じ内容に修正された)のを確認。加賀市立図書館には、9月10日の夕方に電話でこの件について問い合わせをしていた。可児市立図書館に対しては何もしていない。加賀市立図書館の /robots.txt の更新日時は2010年9月11日16時14分15秒、可児市立図書館のものは2010年9月11日14時19分38秒となっている。
それ以外の図書館は、9月14日12時00分の時点で変化なし。
*1 ASPセッションのタイムアウト。検索結果の画面で次ページに進めたときにタイムアウトが発生するか否かによって測定したもの。
*2 10分間に600人が訪れたのと同じ状態(DB接続数が)となる。アクセス数として比較すると、平常時の平均に対して約8倍(中野区立図書館の年間アクセス数は400万とのことなので)にあたる。加えて、通常のブラウザによるアクセスにおいて、1人がASPセッション中にアクセスする回数が平均5回と仮定すると、クローラによるアクセスではDB接続数が5倍という計算になるため、DB接続数で比較すると、通常の40倍の数が発生することになると推測される。
*3 新型の「MELIL/CS」は、「コネクションプーリング接続方式」と「都度接続方式」をサポートしており、旧型にあった「一般的なクローラが来ただけで閲覧しづらくなってしまう欠陥」は存在しないのだから、/robots.txt で拒否する必要性がない。
*4 もしくは、三菱電機ISは、旧型のときに図書館に対して「閲覧しづらくなる事象への対策のために /robots.txt が必要」と説明して設置していた手前、新型だからそれが不要というのでは旧型の欠陥を認めることになるため、「/robots.txt を削除します」と言い出せない状態ということなのかもしれない。
*5 日本のソフト別OPACリストから、他のベンダーの図書館がどうなっているか、地方公共団体を対象にざっくり調べてみたところ、/robots.txt をこんなふうに設定しているのは三菱電機ISだけだった。
*6 たまたまそうなったようにも見えるが。