2016年07月02日
■ 個人情報該当性解釈の根源的懸案が解決に向け前進(パーソナルデータ保護法制の行方 その24)
これまでのあらすじ
このところ、文科省・厚労省・経産省の3省合同会議「医学研究等における個人情報の取扱い等に関する合同会議」*1を傍聴している。これは、昨年11月23日の日記「ゲノム情報医療等実用化推進タスクフォースを傍聴してきた」で書いていた件の、解決に向けた作業会議である。
昨年のタスクフォースで示された課題は、個人情報保護法の改正により、「個人識別符号」にゲノム情報の一部が政令で指定される見通しであることから、これまでそれを非個人情報として扱ってきた「ヒトゲノム・遺伝子解析研究に関する倫理指針」や「人を対象とする医学系研究に関する倫理指針」のルールに見直しが迫られるというものであった。
しかし、11月23日の日記で「議論の背景(連結不可能匿名化の個人識別性)」として書いていたように、課題はそこだけではない。向井副政府CIOからの指摘が出ていたように、個人識別符号に指定されるか否かに関わらず、見直しが迫られるのであり、これまで厚労省系の指針の一部において、氏名等さえ削除すれば個人情報でなくなる(よって、本人同意なく第三者提供できる)かのような、誤った法解釈を前提として書かれている規定の見直しが迫られたものだった。
この課題の解決は、この3年にわたる個人情報保護法制立直しの大詰めとなる局面である。ちょうど3年前、「破綻している日本のデータプライバシー法制」という日記を書いて筆を置いた。このとき「破綻している」としていたのは、Tポイント事業における履歴データの取扱いについてCCC社から得た以下の回答について述べたものであった。そしてその直後、JR東日本がSuicaの乗降履歴を仮名化しただけで日立製作所に提供していた事案が発覚し、そのときもこれと同じ理屈で合法だとされたのであった。今から思えば、日本の個人情報護法制が瓦解する危機の第1波*2が押し寄せてきた時であった。
回答2
(略)第三者提供時において、提供元と提供先のいずれを基準にして個人識別性を判断すべきかについては、現段階では複数の解釈があることは承知しているが、本人の同意なき第三者提供が禁じられている趣旨は、通常、個人データと他のデータとの結合、照合等が容易であり、本人の予想外の個人データが流出することによる、本人の予想を超えた権利の侵害の可能性を避けるものと理解している。この趣旨を鑑みれば、提供先において個人識別性を取得する可能性がなければ、その趣旨に反しないと解釈しているし、現にその旨を明記する岡村久道弁護士等の学説などもある*2。当社において、提供に先立ち、あえてT-IDを置換したコードを作成しているのは、提携先において個人識別性が獲得されることがないのを確実とするためのものである。
破綻している日本のデータプライバシー法制, 2013年6月30日の日記
このときのCCCとJR東日本の理屈は、医学・医療系の分野で普及していた「連結可能匿名化」もしくは「連結不可能匿名化」を真似たものだったのだろう。医学・医療系の分野でそれが許されるなら、民間の一般の利用目的においても同様に許されるという理屈である。
そのような理屈がまかり通るなら、ありとあらゆる人々の詳細なプライバシーデータが、氏名さえ削除すれば野放図に転々流通させてかまわないということになってしまう。これにNo!を突き付けたのが、Suica事案に対する5万5千件ものオプトアウトであった。医学・医療分野でそのような提供が認められているのは、野放図な転々流通ではなく、一定の利用目的の範囲内で、一定の範囲の提供先に限定されて利用されることが社会的に十分に期待されるからであって、一般の民間事業とは一線を画すものだからだろう。
これが個人情報保護法の解釈ではどうなのか。CCCの回答では「複数の解釈があることは承知している」とされていたが、2013年10月に消費者庁が提供元基準を明言し、2015年の通常国会で、個人情報保護法改正の審議の中で、政府見解は従前より一貫して提供元基準であったことが明確にされた。これにより、まず「連結可能匿名化」については、提供元において非個人情報化には当たらないことがはっきりした。CCCも、2014年8月の発表で、オプトアウトを受け付けるとして、個人データの第三者提供に当たるとする解釈に変更していた*3。
一方、本家本元の「連結可能匿名化」は、2014年の文科省・厚労省による指針見直し(「疫学研究に関する倫理指針」と「臨床研究に関する倫理指針」を統合した「人を対象とする医学系研究に関する倫理指針」の制定)で、提供元において個人情報に当たることが意識されていた様子があった。これについては、2014年9月7日の日記「医学系研究倫理指針(案)パブコメ提出意見」に書いている。
残る問題は「連結不可能匿名化」であった。2013年のSuica事案においても、批判が噴出した後になって、対応表を捨てるとJR東日本が言い出しており*4、これが「連結不可能匿名化」に相当するものであり、個人データの第三者提供に当たらないのかが論点となっていた。
「連結不可能匿名化」とは、指針が定義する「匿名化」処理のうち、「連結可能匿名化」とは異なり、加工後のデータと元データとの対応表を残さないものを指す。ここで、加工後のデータと元データとの対応関係は、対応表がなければ照合不可能なのかが問題となる。名称は「不可能」と言うけれど*5、実際には、データの内容が詳細なものであれば、元データとの「データセットによる照合」が可能な場合がある。そのような「データセットによる照合」を、個人情報保護法における容易照合性として認めるのかが論点となる。これについて、直近では「匿名加工情報は何でないか・中編(保護法改正はどうなった その3)」に書いた。
元データとの「データセットによる照合」を容易照合性として認めるかは、未だ公式見解が出ていない。改正法立案担当者らによる解説書(瓜生和久編著, 一問一答 平成27年改正個人情報保護法, 商事法務, 2015年12月)にはこれに関する記述がなく、「匿名加工情報は何でないか・中編」では、「法律時報」88巻1号の記事に立案担当者との質疑応答の様子が掲載されているものが唯一だとした。その後、新たに、「法律のひろば」2016年5月号の濱島秀夫元内閣官房IT総合戦略室参事官の記事で、以下のように明確にこの点に言及されたが、これは元参事官としての個人の見解にとどまっている。
設例2は、移動履歴の蓄積による復元のケースである。個人情報データベースのDB/Aから氏名を削除して、加工用情報DB/Bを作成した。DB/B単体でみれば、特定の個人は識別できない。しかし、個人情報取扱事業者がDB/Aを見れば、一部のデータセットが一致しているので、これは日興太郎のものとわかり、DB/Bの個人情報を復元できてしまう。したがって、DB/Bを匿名加工情報にするには、加工用情報DB/Bにおいて氏名が復元できないように入場・退出日時を丸める(グルーピング)などの措置をとる必要がある。もっとも、一般に移動履歴は蓄積が進めば進むほど、個人情報の復元リスクは高まるため、より多様な措置が必要となると考えられる。(略)
なお、設例1及び設例2の加工用情報DB/Bの情報は、それぞれの個人情報取扱事業者(作成者)において容易照合性のある個人情報である。したがって、(略)
濱島秀夫, 匿名加工情報への期待, 月刊法律のひろば Vol.69 No.5, ぎょうせい, 2016年4月
そして、6月3日には、個人情報保護委員会が、匿名加工方法基準の委員会規則制定に向けて、「匿名加工情報に関する委員会規則等の方向性について」を示したが、この中でも「データセットによる照合」のことが触れられていない。また、4月の行政機関法改正での国会審議でも、この論点を踏まえた議論がなかった。
つまり、「ちょっと個人情報保護委員会しっかりしてよ!」という状況*6であった。
そういう状況で、「医学研究等における個人情報の取扱い等に関する合同会議」(以下、合同会議)はどのように展開していくのか、このままでは抜本的な見直しに至るのは無理かもしれないと心配していた。
合同会議第3回で示された方向性
ところが、合同会議第2回会合で、眠気が吹っ飛ぶ発言が委員から飛び出した。
2点目です。この「個人情報保護法等の改正に伴う主な論点」の8ページの匿名加工情報の取扱いの所です。現在のゲノム指針の匿名性の定義からきちんと見直したほうがいいと思っています。特に、連結可能匿名化という概念が入っているのですが、改正法ではなくて現行の個人情報保護法に照らしても、個人情報の定義から外れないとしか読めない説明がされています。連結不可能匿名化のところについてもきちんと書き分けていただかないと混乱します。対照表を取っている取っていないとか、対照表の有無だけ、あるいはそれを全く残さないということだけで俊別することができるわけではなくて、提供者基準で個人情報の定義はされていますので、そこはきちんと匿名化の定義のところから見直していただいた上で、匿名加工情報の取扱いをどうするのかとしていただきたいと考えております。
事務局が議題に挙げていなかったこの論点を、委員から提起されたのだ。どなたの発言?と委員席に目を向けると、なんと、我らが別所直哉せんせいのご発言ではないですか。どうしたの別所さん!
そして、先週23日に開かれた第3回会合では、連結可能/不可能匿名化概念の見直しの事務局案(案1〜案3)が示されるに至った。

(※1)「匿名化」は、特定の個人を識別することができることとなる記述等の全部を取り除き、照合性も完全に無くし、個人情報に該当しないようにする処理。(例えば個人識別符号を含んでいる、もしくは希少な疾患などで特定の個人を識別できる場合、データを連結することで特定の個人を識別できる場合などは個人情報である)
(※2)「匿名化」は、特定の個人を識別することができることとなる記述等の全部又は一部を取り除く処理とする。なお、個人情報に該当しない情報は、特定の個人を識別できないものに限るとする。
(※3)「匿名化」は、特定の個人を識別することができることとなる記述等の全部又は一部を取り除く処理。(安全管理措置としての*7本人到達性の高い記述の削除する行為を指し、全て個人情報として取り扱う)
(※4)技術の進展等に伴い、(容易)照合性を完全に消失させることが困難な状況になりつつあるため、全て個人情報として取り扱うこととするもの。「非個人情報」を前提とした取扱い(同意手続不要等)ができなくなるため、IC等の手続に当たっては、個情法等の同意取得に係る例外規定等の適用可否を確認する必要がある。
(※5)研究に必要な情報を残した上で、氏名、住所等の本人到達性の高い記述を可能な限り削除し個人識別性を低減させる措置。当該措置を施した情報の位置付けは、対応表を保有しない場合でも個人情報となる。なお、研究に必要な情報にゲノムデータ等の個人識別符号が含まれる場合は、非個人情報化できなくなること等の留意点については、ガイダンスやQ&A等において示すこととする。
合同会議第3回配布資料3-1「指針見直しの方向性(案)(匿名化)」
これら案1〜案3は、いずれも、これまでの指針の「匿名化」(「連結可能匿名化」及び「連結不可能匿名化」)の定義を変更するものとなっているようだ。
案1の「匿名化」定義は、「(※1)」に書かれているように、要するに、「個人情報」の正しい解釈に沿った意味での「非個人情報化」のことであり、案1で新たに設けられる「仮名化」が、「(※5)」に書かれているように、従前の現場で行われてきたであろう実際の連結可能/不可能匿名化に相当するものとなっている。
案2、案3の「匿名化」は、「(※2)」及び「(※3)」に書かれているように、照合による識別性を失わせることを求めず、「特定の個人を識別することができることとなる記述等の全部又は一部を取り除く処理」という、要するに、情報公開法6条2項の部分開示に似たもの*8で、これも、従前の現場で行われてきた連結可能/不可能匿名化に近いものということであろう。
案1の「仮名化」と、案2の「匿名化」の多くの場合(表の右の列)は、「個人情報」の正しい解釈上、提供元において個人情報に該当するものとなる。これは、これまで「連結不可能匿名化」と呼んでいたものついても該当するのであり、現行のゲノム指針が「個人情報を連結不可能匿名化した情報は、個人情報に該当しない。」と明言しているところを撤回する趣旨の案だということになる。
ということは、事務局案は、元データとの「データセットによる照合」を容易照合性として認めることを前提としていると推察される。ただ、事務局資料にはそのことが明記されていない*9。
この事務局案に対する委員の反応は、総じて反対とする声はなく、難しすぎてよくわからないから次回でもっとわかりやすく整理してほしいというような声が相次ぐ形となった。
事務局の整理が今ひとつ明確なものとならないのは訳アリだと思われる。なぜなら、今回の見直しの根源は、これまでの指針が個人情報保護法の解釈を誤っていたのを改めるところにあり、まずはその誤りを認めることから始めなければ、すっきりした説明とならないところ、役所としては「間違っていました(テヘヘ)」とはなかなか言い出せない*10からだ。
指針が法解釈を間違っていたと指摘するには、元データとの「データセットによる照合」のことを言わねばならず、その解釈の公式見解が出ていない段階では説明が難しい。だが、条文レベルで指針の間違いを指摘できることに最近になって気づいた。2年前の「医学系研究倫理指針(案)パブコメ提出意見」のときには見落としていたが、指針の「匿名化」の定義は以下のようになっていて、明らかに誤りがあると指摘できる。
医学系研究倫理指針:
特定の個人(死者を含む。以下同じ。)を識別することができることとなる記述等の全部又は一部を取り除き、代わりに当該個人と関わりのない符号又は番号を付すことをいう。なお、個人に関する情報のうち、それ自体では特定の個人を識別することができないものであっても、他で入手できる情報と照合することにより特定の個人を識別することができる場合には、照合に必要な情報の全部又は一部を取り除いて、特定の個人を識別することができないようにすることを含むものとする。
ゲノム研究倫理指針:
提供者の個人情報が法令、本指針又は研究計画に反して外部に漏えいしないよう、その個人情報から個人を識別する情報の全部又は一部を取り除き、代わりに当該提供者とは関わりのない符号又は番号を付すことをいう。資料・情報に付随する情報のうち、ある情報だけでは特定の人を識別できない情報であっても、各種の名簿等の他で入手できる情報と組み合わせることにより、当該提供者を識別できる場合には、組み合わせに必要な情報の全部又は一部を取り除いて、当該提供者が識別できないようにすることをいう。匿名化には、次に掲げるものがある。(略)
このように、いずれの指針も、個人情報保護法の「個人情報」定義の裏返しを「匿名化」と規定して、「個人情報」に該当しないものとしようとした意図が読み取られる。前半の「……を取り除き」の部分は、個人情報定義の「当該情報に含まれる……その他の記述等により特定の個人を識別することができるもの」の裏返しであり、後半の「……であっても……場合には……」の部分は、個人情報定義の「(他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。)」を裏返したつもりだったのだろう。
ところが、後半が裏返しになっていないのである。法律は「他の情報と容易に照合することができ」としているのに、指針では、どういうわけか「他で入手できる情報」との照合に限定してしまっている。つまり、自組織内の元データとの照合は問わない形になっており、個人情報保護法の「個人情報」該当性を失わせるものにはなっていないのである。
どうしてこうなったのか。おそらく、指針にこの定義が最初に設けられたとき、法律の「他の情報」を解釈する際に、自組織内の元データとの照合のことが全く念頭になく*11、「他の情報」の意味をわかりやすくしようとの親切心で余計な文言を付け加えたものではなかろうか。
もしくは、個人情報該当性の単位を、組織単位ではなく、取り扱う人(従業者)単位で捉えていたために、「他で入手」の主体を従業者として想定して、組織内に元データがある場合であっても従業者が元データを「入手」できない状にあれば個人情報に当たらないと解釈していたのかもしれない。法律上は組織単位であるので、このような考え方もまた誤りである。(これについては、「Q14問題とは何か(パーソナルデータ保護法制の行方 その9)」で書く予定。)
事務局資料は、ここの誤りについて触れていないが、案1の「匿名化」の定義「(※1)」を見れば、従来の定義とは変えていることがわかる。定義を変えるからには理由が必要となるところ、事務局資料は、その必要性を次のように位置付けている。
合同会議第3回配布資料3-1「指針見直しの方向性(案)(匿名化)」
- 現行指針では、匿名化された情報は、対応表を保有しない機関においては個人情報に該当しないとされている。しかし、改正個人情報保護法の施行後に、ゲノムデータの全部又は一部が個人識別符号に位置付けられた場合、研究に用いられる情報にこれらの個人識別符号が含まれるときは、従来の匿名化処理を行っても非個人情報化できなくなる。
- また、現行指針では、「照合」に必要な情報の全部又は一部を取り除いて、特定の個人を識別することができないようにしなければ、匿名化したことにならないとしている。改正個情法等において、匿名加工情報(非識別加工情報)の概念が導入され、当該情報への加工の基準が示されるため、匿名加工(非識別加工)より個人識別性の低減度合いが低い匿名化処理を、非個人情報化とみなすことはできなくなる。
1つ目はよいとして、2つ目の点。なるほど、「匿名加工より個人識別性の低減度合いが低い匿名化処理を、非個人情報化とみなすことはできなくなる」とは、なかなかうまい理由だ。これならあくまでも法改正に伴って必要となる改正なのだという位置付けにできる。ただ、残念ながら、「非個人情報化とみなすことはできなくなる」は、改正法の匿名加工情報の解釈として正しくないと指摘せざるを得ない。
なぜなら、「匿名加工情報は何でないか・前編(保護法改正はどうなった その2)」の「匿名加工情報の定義に該当するからといって36条〜39条の義務が課されるわけではない」で述べたように、「匿名加工情報」の制度は、従前の匿名化手法を制限するような規制強化ではないとされているからである。
合同会議での事務局の説明では、もう少しうまい言い方がされていた。厚労省の事務局は、「ちょっと難しい言い方になるが、匿名加工基準が示されたときに、今まで、研究の場合に匿名化と言って名前・住所を適宜削除していたものが、それで非個人情報としていたのが、匿名加工情報より粒度の細かい情報で残っていた場合は、個人情報でないと言い切れるのかという問題が出ている。」と説明していた。
この説明でもまだ苦しい。結局、これまで「匿名化」と称して現場で行われていた加工方法が、多くの場合で非個人情報化になっていなかった実態を踏まえて、それが非個人情報化になっていない理由を示さないと、なかなか理解されにくいだろう。
そのためか、医師会の委員から、資料にある「非個人情報化」が何なのかがわからないので、再度整理してほしいとする指摘が出ていた。これに対して座長から回答を促された事務局は、「非個人情報とは個人情報に該当しないという意味だが、何が個人情報に該当しないかをこちらとしても示しきれないところが悩ましいところだ。少なくとも集計表といったものは非個人情報だと考えている。」と述べるにとどまった。
ここはやはり、元データとの「データセットによる照合」のことを言わなければ、理解されないだろう。
そんな中、別所委員からこんな発言が飛び出した。
混乱の原因は定義のわからないものが多いことだと思うのです。連結可能匿名化も特殊な言葉で、他で存在していないものです。用語は法律用語に全部統一していただけないか。匿名加工はちゃんとした法律用語であって、行個法の方でも新しい定義が出た。これらは範囲が明確で、それ以外の言葉を使うこと自体が混乱を招くと思っている。法律に戻れば大丈夫なのであり、匿名化とか個人情報は、法律用の用語にきちんと平仄を合わせていただきたい。なので、連結可能匿名化とか連結不可能匿名化という用語もやめていただきたいと思っている。そもそも特別な定義をガイドラインでできるものではなく、法律の枠を超えることはできないのだから。そこをきちんとしていただきたいと考えています。
もう一つは、混乱が起きているのは、ゲノム情報が個人識別符号になるかどうかということだけではなくて、その前の段階があって、今まで対照表のありなしが議論のポイントになっていましたが、実は、対照表のありなしは意味がないということを、みなさんご理解いただいた方がいいのではないかと思っています。対照表が仮になかったとしても、元々のデータが、特定の人についてユニークなデータだった場合には、名前を外そうと、住所を外そうと、どうしても個人情報なのであり、それは現行でそうなんですね。ですので、対照表があるとかないとかで個人情報に該当するしないという概念が、個人情報保護法にはないのですよ。そういうことの誤解がある。仮にゲノム情報が個人識別符号に該当しないとしたとしても、ユニークな情報の集まりなものについて言うと、個人情報として取り扱わざるを得ないのだということをですね、まずそもそもの前提として、ご理解いただく必要があるんではないかと思っているんです。これ、たぶん、私が解説すべきところではないんですけど(笑)、個人情報保護委員会の方、間違っていたらご訂正ください。
医学研究等における個人情報の取扱い等に関する合同会議, 第3回 (議事録未公表につき、傍聴時メモより)
前半には全く賛成できないが(後述)、後半、元データとの「データセットによる照合」のことが述べられている。内容も正確だ。どうしちゃったんだ別所さん!(笑)
これに対して個人情報保護委員会事務局からのコメントはなかった。ただ、その後、議論が続き、横野委員から、「表の左列の非個人情報というのは、改正法の匿名加工情報とは同じものなのか、別のものなのか。」との質問が出た際に、厚労省の事務局が、「これは個人情報保護委員会に教えていただきたいところだが、「匿名加工情報 = 非個人情報」ではないと理解している。今まで使っていた連結不可能匿名化が匿名加工情報とどういう関係性を持つかもかなり議論があるかと思う。非個人情報とは何かというときに、少なくとも集計表みたいなものは個人情報ではないが、どれくらい個人情報を削ったら非個人情報かというのは、なかなか難しいところがある。」と答えると、個人情報保護委員会事務局の山本参事官から次の発言があった。
慎重に答えなければならないが、基本的に先ほど別所委員がおっしゃっていただいたことと同じことを言いたい。個人情報保護法における個人情報というのは、特定の個人を識別できるものとしている。個人情報かどうかは、その性質・性状による。具体的にどのような枠組みで理解するかについては、多種多様でありなかなか難しいというのが、先ほどの市川補佐の説明かと思う。ここの考え方は、さきほど別所委員おっしゃられたように、個人を識別できるゲノムデータが仮にあったとしたら、名前が山本という個人かは別にして特定の個人がわかるから、個人情報であるということになるのが、まずその1である。その2として、今改正で匿名加工情報というものができたが、これは、個人情報を、特定の個人を識別できないように加工したものを、匿名加工情報と、少し縮めて述べているが、そういう概念である。例えば、「個人情報保護委員会事務局参事官の山本」という情報があれば私のことだと誰しもわかるが、この役名、名前とかを削除していく、削除したものを、削除するような加工を施したものを匿名加工情報としている。なので、資料3-1の表については、対応表の有無という問題も、匿名加工のような具体的な加工プロセスも典型的な一例として意識していただく必要がある。ただし、個人情報というのは「個人に関する情報」というその属性、性質に着目する必要があるというそもそものところも意識していただく必要がある。
医学研究等における個人情報の取扱い等に関する合同会議, 第3回 (議事録未公表につき、傍聴時メモより)
誠に残念なことであるが、個人情報保護委員会事務局は、この質問に答えることができなかった。「その1」の点はよいが、「その2」について、答えようとして答えることができていない。ただ、「別所委員のおっしゃる通り」と2回も発言されたのだから、もう、別所委員の指摘通りということでいいではないか。
この直後に、医師会の委員から発言があり、NDBでもハッシュ関数をかけて連結可能匿名化をしているが、非連結にしても、別所委員の指摘のような状況が実際に起こっていることがわかってきたと、要するに、別所委員指摘のケースは個人情報であると言うべきだと、肯定する発言があった。この点に反対する声はなかったので、この点については合意に達したと言えるのではなかろうか。*12
この考え方が事務局資料に明記されなかったのは、個人情報保護委員会のお墨付きがない限り、事務局から独自に言い出すわけにはいかないということであろう。そうすると、個人情報保護委員会がなすべきことは、別所委員の解釈と同じことを、公式見解として出すことだ。
非個人情報となる条件を示せというのが難しい問いであるのは理解するところだが、非個人情報とならない条件の一つを示したのが別所委員の指摘である。そうした条件を列挙していくことでしか、境界は明らかになっていかないのだから、まずはこの条件を公式に示すことが最低限のできることであろう。
6月3日に出た個人情報保護委員会の「匿名加工情報に関する委員会規則等の方向性について」を見ると、次のように書かれており、匿名加工基準の委員会規則には、ほとんど何も基準を示さないつもりらしいことがわかる。
2.委員会規則及びガイドライン等の記載の方向性
(1)規則における規定について
①加工に関する基準について(第36条第1項)
(ア)本項の趣旨本項の規則は、匿名加工情報が特定の個人を識別すること及びその作成の元となった個人情報を復元することができないものであることから、そのような状態とするために必要な加工手法その他の必要な事項を定めるものである。
(イ)規則で定める基準の方向性
基準では、匿名加工情報を作成する事業者全てに共通する一般的な加工手法その他最低限の規律を定めることとし、これに従って事業者が具体的にどのような加工を行うかについては、取り扱う個人情報、取扱い実態等に応じて定めることが望ましいことから、認定個人情報保護団体が作成する個人情報保護指針等の自主的なルールに委ねることとする。
このようにせざるを得ないのは理解できるにしても、「最低限の規律」として、2条9項の「匿名加工情報」に該当させるための非個人情報化には、別所委員の指摘で言うところの「特定の人についてユニークなデータ」、「ユニークな情報の集まりなもの」とならないよう加工することを最低限の条件の一つとして、委員会規則に明示的に規定してはどうか。それが、我々の言葉で言うところの、元データとの「データセットによる照合」のことである。
これまで、個人情報保護委員会(発足前においては内閣官房IT総合戦略室)が、「データセットによる照合」を容易照合性の一つと認めているのか認めていないのか、ずっと謎なままで来ていた。今年の行政機関個人情報保護法の改正においても、その点を個人情報保護委員会がはっきりさせないことが遠因となって、行政管理局が混乱させられたようにも見えた。
もっとも、これをはっきりさせられなかった事情はわからなくもない。もし、「データセットによる照合」を容易照合性の一つと認めれば、仮名化しただけでは(多くの場合)非個人情報とならないことになるから、特に、医学・医療の領域で「連結不可能匿名化 = 非個人情報化」としてきたことが誤りだったということになり、この領域の業務が立ち行かなくなることが懸念され、そう易々と認めるわけにはいかないという面はあったのだろう。
だが、上記のように、今回の3省合同会議で、仮名化は非個人情報化ではないとし、指針のルールを抜本的に見直そうと前進し始めたのである。ならば、もはやそのうような懸念はないのだから、むしろ見直しを前進させるためにも、この際、その前提となる「データセットによる照合」の容易照合性を、個人情報保護委員会が公式に認めるべきである。
依然として混沌としている見直し案
合同会議第3回では、案1〜案3のどれにするかについて、若干の議論があった。医師会の委員からは、「頭を整理すれば、案3しかない」との声が挙がった。その理由ははっきりしないが、「別所委員のおっしゃったことは案3だと思う。」との発言もあったことから、全ての場合においてk=1になるとの誤解*13があるのではなかろうか。
あるいは、もしかすると、案1の「匿名化」の解釈にブレがあって、そのせいで混乱が生じているのかもしれない。
案1の「匿名化」の説明は、「(※1)「匿名化」は、特定の個人を識別することができることとなる記述等の全部を取り除き、照合性も完全に無くし、個人情報に該当しないようにする処理。」となっている。当初私は、これを、提供元において非個人情報化する処理のことであり、個人情報保護法の「個人情報」定義のちょうど裏返しを書いたものだと思っていた。しかし、改めて見ると、「照合性も完全に無くし」とあり、完全にとはどういうことだろうか?という疑問が湧く。もしかすると、どこへ提供しても提供先で照合性が完全に無くなることを求めているのかもしれない。そうだとすると、続く文の「個人情報に該当しないようにする」というのが、提供先においても、どうやっても個人情報に該当するものとなり得ないようにするという意味なのかもしれない。
つまり、図1の表の左列が「非個人情報」とされているのは、「提供元において非個人情報」という意味ではなく、「どこにおいても必ず非個人情報となるもの」という意味なのかもしれない。そう解釈すると、その類推から、案3の左列が「なし」というのは、そんな場合はほとんどありえないから「なし」に等しいということと理解できる。実際、「なし」の注釈「(※4)」にそれらしきことが書かれている。医師会委員の発言は、そういう意味で述べられたのではかろうか。
しかし、事務局の説明からすると、そういう趣旨ではないようにも聞こえた。
事務局資料には続きの資料3-2「指針見直しの方向性(案)(インフォームド・コンセント等)」がある。こちらに、同意などの手続きルールの見直し案が示されており、案1〜案3のどれを採用するかでルールがどう変わるかが検討されている。案1を採用すると変更点が最も少なく、案3を採用すると変更点が最も多いというものになっている。
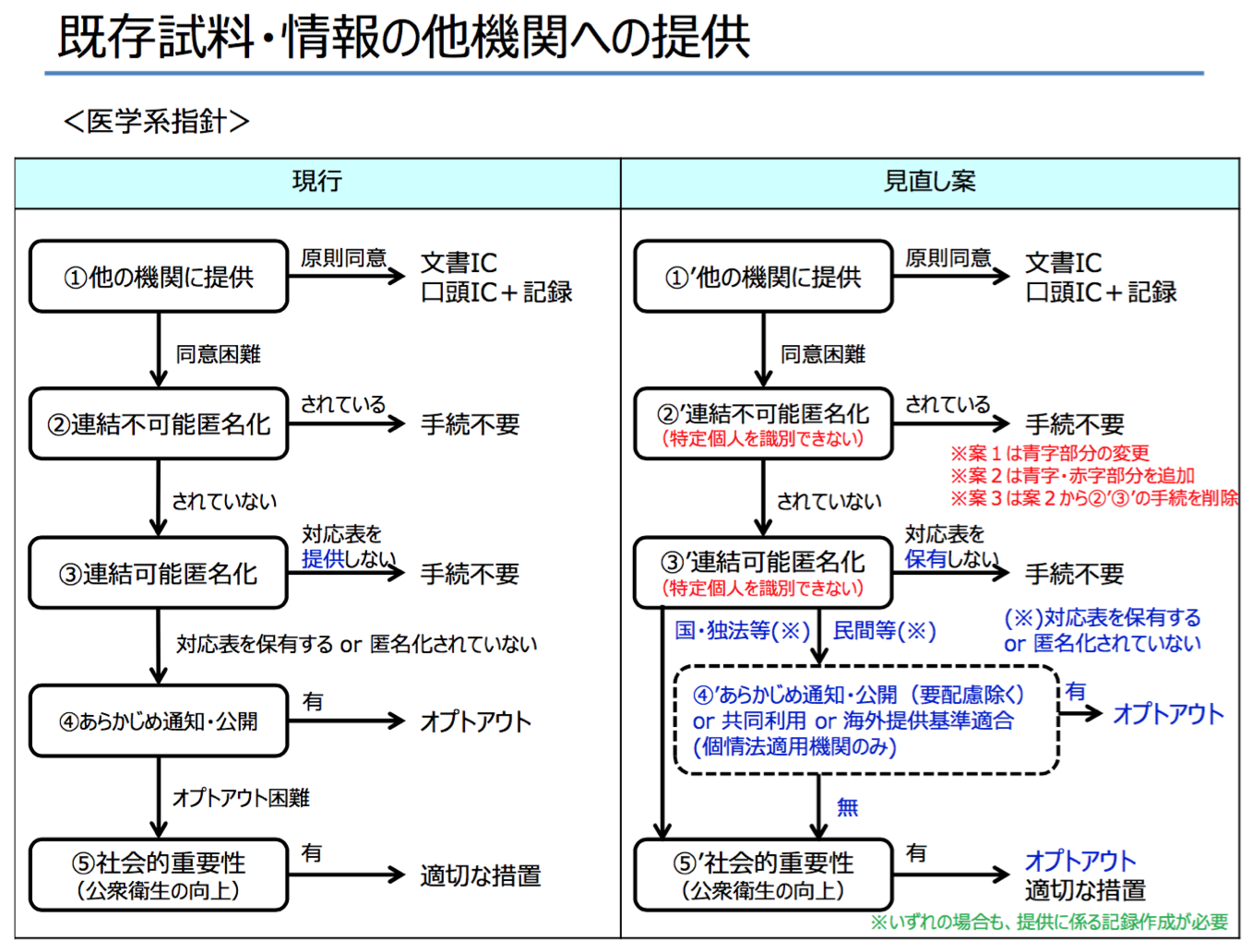
案3を採用すると、これまでの指針のルールの②と③を削除することになるという。つまり、「手続不要」としていたルールの場合分けの全部をなくすということだ。②と③は、これまで、連結可能/不可能匿名化すれば非個人情報になるという前提で「他機関への提供」を「手続不要」としていたものであり、これをやめるということになる。
図1の「匿名化」定義の場合分けは、こちらの手続きルールをどうするかを出発点として見た方が趣旨を理解しやすい。「手続不要」としていた②と③の場合分けをもうやめると決めてしまえば、図1の左列は、分類上不要となるので、案3では「なし」と書かれているのだと理解できる。
つまり、図1の案3で左列が「なし」となっているのは、「そのような情報は存在しない」という意味ではなく、「指針のルール上区別を要しない」ということだろう。実際、案3の注釈「(※3)」には「全て個人情報として取り扱う」と書かれており、法的な個人情報該当性の評価から離れて、「個人情報とみなして取り扱う」という意味であろう。
それを踏まえて、案2について見てみると、案2は、手続きルールの場合分けに「特定個人を識別できない」か否かを分岐条件としている。これの定義がはっきりしない(図1には「特定の個人を識別できないものに限る。」としか書かれていない)が、事務局からの口頭説明では、案2のデメリットとして、「匿名化」処理をした後、提供に際して手続不要かを判断するには、処理後のデータが個人情報に該当するかの法的な評価が必要となる旨の説明があったので、これは「法律上の個人情報に該当しないもの」という意味だろう。
そうすると、図1の左列と右列は、案2では法的評価によって決まるのに対して、案3では法的評価に関係なく右列と「みなす」ということであり、案ごとに左列と右列の趣旨が異なっているわけで、このことが理解を難しくしている。
では、案1はどうなのか。右列の「仮名化」は、処理方法は「(※5)」に書かれている*14ものであり、その処理結果が法律上の「個人情報」に該当するかは、データの内容による。k=1となる場合が多いであろうが、k≧2となる場合もある。それにもかかわらず、「(※5)」には、「当該措置を施した情報の位置付けは、対応表を保有しない場合でも個人情報となる。」と書かれていて、常に「個人情報」だと言っている。
これをどう理解するか。医師会委員の発言にもあったように、事務局も「全ての場合においてk=1になると誤解」しているのかもしれない。あるいは、案3同様に、法的評価から離れて、「個人情報とみなして扱う」という意味ともとれる。これがどちらなのかが、資料からも口頭説明からもはっきりしなかった。
つまり、まとめると、第3回の整理ではっきりしていないのは以下の点である。
- 案3の「なし」の意味は、そのような情報はありえない(注釈「(※4)」が言うように)という意味なのか、それとも、「個人情報とみなして扱う」から分類上不要という意味なのか。
- 案1の「仮名化」について常に「個人情報となる」としているのは、「全ての場合においてk=1になると誤解」しているせいなのか、それとも、「個人情報とみなして扱う」という意味なのか。
- 案1の「匿名化」定義が言う「非個人情報化」の意味が、提供元においての(法律上の)非個人情報化のことなのか、それとも、「どこにおいても必ず非個人情報となるものに加工する」ことなのか。
私の意見
これらをどう整理するか。私の意見を述べると以下の通りである。
1.の点については、前記の通り、「(※3)」に「全て個人情報として取り扱う」と書かれているので、事務局の趣旨としても、後者ということでいいだろう。注釈「(※4)」が言っている「技術の進展等に伴い、(容易)照合性を完全に消失させることが困難な状況になりつつある」云々は蛇足だ。前者の解釈は法律論として乱暴すぎる。個人情報保護法はそこまでのことを求めてはいない。たしかに、昨年の改正法の議論の中で「照合性を完全に消失させることが困難な状況になりつつある」的な話が出てきたが、それは、匿名加工情報の制度を設けるに際して、再識別禁止義務の規定を設ける必要性の根拠として、可能性をゼロにできないという程度の意味で言われていたのであって、そこまで加工しない限り提供できないという趣旨のものではなかったわけで、そこを混同してはいけない。1.が後者の趣旨であるなら、この蛇足は書く必要がないし、書かない方が誤解を招かなない。
2.の点については、前者は誤解に基づくものと言えるので、後者とするしかない。「(※5)」の「個人情報となる」との記述は、「個人情報とみなして扱う」と書いた方がよい。「みなす」と書くわけにはいかないのであれば、案3の「(※3)」のように「個人情報として取り扱う」と書けばよい。(より正確に言えば、「一部の場合を除き個人情報となる。個人情報とならない場合であっても、個人情報として取り扱う。」といったところか。)
3.の点については、前者とするべきだ。後者のような加工を個人情報保護法は求めていない*15。改正法で新設される「匿名加工情報」でさえ、そこまでの加工を求めるものとはおそらくならないだろう。後者とした場合、はたしてどうすればそのような情報となるのかの確定が難しくなる。前記の通り、事務局も「何が個人情報に該当しないかをこちらとしても示しきれないところが悩ましいところだ」としていたわけで、後者だとこれが本当に難しくなる。ここを前者とすれば、法的評価と一致するので、「データセットによる照合」が容易照合性に当たることを認めれば、その意義はある程度明確にできるだろう。
このような混乱が生じるのは、指針でのルールの対象と法律上の客体とを1対1対応させようとして、ルールの決定と法律への適合性とをいっぺんに決めようとするからで、そこに無理が生じているのだろう。
ここで、前掲の別所委員の発言に「全く賛成できない」としたことが関係してくる。別所委員は、「用語は法律用語に全部統一していただけないか」と述べたが、私の意見は真逆だ。
むしろ、指針の用語(指針でのルールの対象を指す用語)は、法律用語とは別にして、独立したものとするべきと考える。「個人情報」の語すら指針では使わないのがよい。その上で、指針のルールがどのようにして個人情報保護法に適合するものとなっているかを、指針とは別の解説として書けばよいのだ。
つまり、この方法に従えば、案1を選択した場合、「仮名化」(2.の後者)の処理方法を定義して、指針のルールは「仮名化」の語を用いて規定する*16ことになる。その上で、各ルールが個人情報保護法に適合している理由を「個人情報」の語を用いて解説することになる。
このようにすれば、「個人情報とみなす」といった規定にしなくて済むし、指針のルールを策定する際に、法律上の「個人情報」概念に囚われすぎることなくある程度自由に検討することができる。
そもそも、指針の読者である研究実施者からすれば、何を知りたいかは、何を守ればいいのかという指針のルールそのものであって、それが個人情報保護法上どういう関係にあるかなどということは、普通は興味がないことで、指針の制定者に任せておきたいところだろう。これまでの指針は、法律の用語を用いて、「個人情報保護法を遵守する必要がある」などと書いていたものだから、見通しの悪いルールとなったばかりか、「何が個人情報なんだ!」といった不満が生じ、個人情報保護法に対する不信感さえ生じていた。
これを踏まえると、合同会議第3回配布資料3-1「指針見直しの方向性(案)(匿名化)」の4頁に書かれている、以下の案には大反対である。*17
照合性と容易照合性について
現状
現行の医学系指針において、個人情報の定義は「他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。」と規定している。一方、匿名化の定義は「他で入手できる情報と照合することにより特定の個人を識別することができる場合には、照合に必要な情報の全部又は一部を取り除いて、特定の個人を識別することができないようにする」と規定している。このため、「特定の個人を識別することができない」情報の考え方が、指針内で整合していない。(なお、ゲノム指針における当該考え方は「照合性の可否」に統一されている。下記<現行指針における定義>参照)
このため、医学系指針における個人情報の定義を「他の情報と容易に照合する」から「他の情報と照合する」に見直すこととする。
合同会議第3回配布資料3-1「指針見直しの方向性(案)(匿名化)」
法律で民間部門と公的部門とで「容易に」のあるなしが異なるところ、指針もバラバラだったから、厳しい方の「容易に」なしに合わせるということと思われるが、むしろ、指針で「個人情報」の語を定義しないべきである。
指針の適用対象者には、独立行政法人と国立大学(独立行政法人等個人情報保護法が適用される)や私立大学(個人情報保護法の4章が適用される)、市民病院(その自治体の条例が適用される)等が含まれ、それぞれの法律・条例ごとに「個人情報」の定義が異なっている。それらに共通の指針を策定しているのだから、定義はこれら全部をカバーする最も広い範囲とするというのが、「容易に」なしに合わせるとする見直し案の考え方だろうが、そうやっていると、無用に厳しいルールとなっていくおそれがある。
だが、上記のように、指針で「個人情報」の語を用いずにルールを規定すれば、この問題を避けて通ることができる。ルールが各法律・条例に適合しているかは、解説で確認しておけばよいことだ。
ところで、もう一つ、事務局資料3-1にはおかしな点がある。資料の最初に出てくるこの図である。
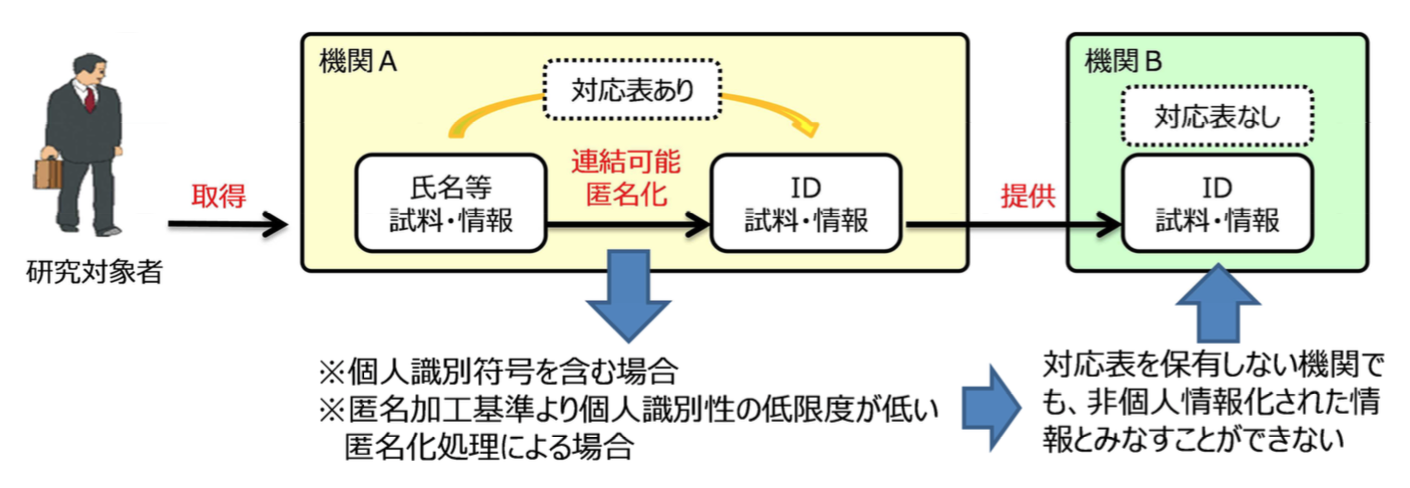
この図では、提供先となる受領者「機関B」において、「非個人情報化された情報とみなすことができない」とされているが、元データが「※個人識別符号を含む場合」のときはそれで正しいが、「※匿名加工基準より個人識別性の低減度が低い匿名化処理による場合」のときは、正しくない。
後者を問題とするときは、提供元で元データとの照合ができるデータならば提供元において個人情報であるから提供に際して同意が原則となるという話であり、提供先の受領者でもそれが個人情報となるとは誰も言っていない*18。合同会議の第1回でも、提供先での個人情報該当性は提供元とは独立に判断されるとしていたはずだ。
これがただの誤記ならばよいのだが、どうもそうには見えない。図1の表の注釈を見ると、提供元で個人情報として提供したものは、提供先でも必ず個人情報となるのを前提としているように見える。特に、案1の「仮名化」と案3の「匿名化」は、提供先でも個人情報として扱うという趣旨で書かれているように見える。
これは、従来の指針が、連結可能/不可能匿名化したデータについて、その受領者に対しても安全管理措置義務を課していた*19ことと関係するかもしれない。
すなわち、これまでの指針は、連結可能/不可能匿名化されたデータの提供を受けた受領者にとって、それが非個人情報であるにしても、元が連結可能/不可能匿名化データであったからには、引き続き匿名化データとして扱うというルールになっていた。したがって、案1で「仮名化」概念を新たに設けるにしても、同様の性質を持たせる必要がある。
この点、案3や、案1の仮名化(2.の後者)を採用する場合、「個人情報として取り扱う」ということだから、不都合はない。つまり、受領者において、受領したデータが「個人情報」に当たらないものだとしても、指針のルールでは、「仮名化データ」としてルールの対象とするのである。
ここでも、やはり、「個人情報とみなす」とか「個人情報として取り扱う」と規定すると、「個人情報じゃないのに?」などと話がややこしくなるので、指針の規定には「個人情報」の語を用いず、「仮名化データ」で通して、法的評価は解説に任せるのがよいと思う。
このように整理すれば、矛盾のない図が書けるのではなかろうか。
さて、以上を踏まえて、案1〜案3のどれを選択するかであるが、私の一推しは、どれからも少しずつ改変した案4(新規)である。
案1の問題点は、案1左列の「匿名化」は、現行の指針の「匿名化」に係る義務規定を維持したまま、「匿名化」の定義を変えてしまうというものであり、その変更された定義は、「非個人情報化」そのものであり、従前の現場での「匿名化」処理の実態からかけ離れているので、現場からの抵抗が強いと予想されることである。また、従前の現場での「匿名化」処理の多くは、案1で新設する「仮名化」に当たるわけだから、「仮名化データ」に係る義務規定に従うことになるので、現行の「匿名化」に係る義務規定は、あまり使われなくなると予想され、そのようなレアケースのためだけに、連結可能/不可能匿名化の概念を残すのは、複雑さが増すばかりで無益であるように思える。というか、それ以前に、連結可能匿名化については、提供元で元データと照合できるので常に個人情報なのであり、非個人情報化したものを「匿名化」としているのに「連結可能匿名化」というのは、定義矛盾となっており、ここは明らかにおかしい。案1では、連結可能匿名化は存在しないことになるはずである。
他方、案1の利点は、現場の処理の実態に即した「仮名化」を新たに定義することで、法律上の個人情報該当性から一旦離れて、取扱いルールを決めることができ、提供先の受領者にも統一したルールを課すことがシンプルに実現できそうなところにあるように思える。
これに対し、案2は、「匿名化」の定義を現場の実態に合わせて変更しつつ、現行の指針の「匿名化」に係る義務規定を維持するというものであるから、現場からの抵抗は抑えられそうなところが利点である。
案2の問題点を探してみると、図2のルールを見ると、結局「特定個人を識別できない」場合にのみ「手続不要」となっているから、「連結不可能匿名化」の概念はもはや不要であるように思える。端的に言えば、これまで非個人情報化の手段として「連結不可能匿名化」の概念を用いてきたが、実は非個人情報化になっていなかったということで改正するのであるから、もはやその概念は不要ではないかということである*20。さらに、図2の③のところ*21で、「連結可能匿名化」なのに「特定個人を識別できない」と条件付けしているのは、存在し得ないものを指していることになる*22。つまり、案2では、連結可能匿名化と連結不可能匿名化の区分は無用であり、単に、左列と右列の区別、すなわち「特定個人を識別できない」か否かだけで区別すればいいということになるはずだ。
対して、案3は、連結可能匿名化も連結不可能匿名化も、どんなデータでも「個人情報として扱う」というものである。これに対しては、さすがに反対の声が出るはずである。合同会議第3回でも、複数の委員から、非個人情報が世の中に存在しないとまでは言えないので、2つに分けざるをえないとして、案3には反対する意見が出た。
このように、いずれの案にも問題があるので、新たに案4を提案したい。
案4は、案1の右列の「仮名化」はそのままに、左列の「匿名化」を「非個人情報化」に変更する案である。なお、ここで言う「非個人情報化」は、提供元において個人情報に当たらなくするという意味(前記 3.の前者)である。これにより、現行指針の「匿名化」定義とその取扱いルールは一旦消えてなくなる。代わりに「仮名化」が従来の「匿名化」(現場での実態における)のことであるとし、その取扱いルールは、個人情報に該当するとみなして保護法に適合するルールとする。そして、左列に当たる「非個人情報化」したデータについては、「手続不要」のルールとする。
これは、案2の「匿名化」を「仮名化」に差し替えたものに近い(「匿名化」の定義と取扱いルールが消えてなくなるので、連結可能と連結不可能と区別もなくなり、前記の矛盾点が解消する。)が、違いは、案2ベースでは、「仮名化」したものについて、それが非個人情報に当たるときは、「手続不要」のルールとなるのに対し、案1ベースでは、個人情報として扱うとしている点である。ただし、案4では、「非個人情報化」を規定することから、「仮名化」かつ「非個人情報化」という状況が存在し得て、「非個人情報化」を優先することにより、仮名化に相当するデータ加工であっても、それが「非個人情報化」したものとも言えるときは、「手続不要」のルールを適用できる。
案3との違いは、「匿名化」を「仮名化」に差し替え、「非個人情報化」の規定を加えたものと言える。後者により、前記の「非個人情報が世の中に存在しないとまでは言えない」とされる案3の問題点が解消される。
案4で、加工の方法として、案2、案3の「匿名化」の方法(情報公開法6条2項の部分開示に近いもの)を採用せず、案1の「仮名化」の定義を採用するのは、もはや、個人情報該当性から離れて、安全管理措置のための加工方法の一つを規定しようとしているのだから、案2、案3の「匿名化」のような、個人情報定義の一部を残すことには、もはや意味がないので、それよりも、自由に決められる案1の「仮名化」定義の方が相応しいと考えた。
「仮名化」定義の加工方法(「(※5)研究に必要な情報を残した上で、氏名、住所等の本人到達性の高い記述を可能な限り削除し個人識別性を低減させる措置」)は、ちょうど、ICH(日米EU医薬品規制調和国際会議)の E15(ゲノム薬理学における用語集)(2007年)における「coded data」(日本で言う連結可能匿名化に当たる)の定義、「Coded data and samples are labelled with at least one specific code and do not carry any personal identifiers.」における、「do not carry any personal identifiers.」の部分に相当するものになっているように思える。「personal identifiers」は公式日本語訳では、「個人識別情報」と訳されている。「個人識別情報」という語もまた誤解を招きかねない(個人情報自体と混同されそうな)感じがしなくもないが、こうした国際的な用語に合わせていくことも重要だろう。*23
今年4月に採択されたEUの一般データ保護規則(GDPR)では、「pseudonymisation」(仮名化)の語が定義されており、これもちょうど、これまでで言う連結可能/不可能匿名化が該当するものとなっている。GDPRでの定義は、「‘pseudonymisation’ means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person;」となっており、元データとの照合について、ICH E15のように「code」による方法に限定せず一般化して書かれているから、「データセットによる照合」のことも想定内のようにも見える。この定義では、分離されて扱われることと、技術的・組織的対策がなされることが定義中に含まれている。このような定義方法も見倣うべきところがあるかもしれない。
なお、GDPRでは、「pseudonymisation」を、processing of personal data の一形態としている点に注意したい。つまり、GDPRでは、仮名化は非個人情報化を意味するのではなく、あくまでも個人情報としての処理であって、安全管理措置として奨励される処理方法の一つとして規定されているにすぎない。
このように、やはり、国際的整合性からも、データの加工方法と個人情報該当性とは、初めから直結させて定義しようとするのではなく、加工方法の目的と定義がまず先にあって、それに対する個人情報該当性は後から評価するという形で進めていくのがよいように思える。
指針における匿名加工情報
合同会議第3回では、改正法の「匿名加工情報」との関係も論点となった。委員の発言を聞いていると、案1〜案3の「匿名化」と同じものと捉える委員も少なくないように見えた。
案1の「匿名化」は非個人情報化なので、改正個人情報保護法2条9項の「匿名加工情報」と同じといえばそうかもしれない*24。案2、案3の「匿名化」は、個人情報のまま(となることが多い)なので、「匿名加工情報」とは異なる概念である。案1の「仮名化」も同様である。
どの案を採用する場合も、「匿名加工情報」の制度は、指針が規定の中心とする「仮名化」の取扱いとは別のものであり、これまで指針に規定してこなかったものであるから、今回の指針改正で「匿名加工情報」のことを取り入れる必要性は薄いように思える。法改正に伴って規制強化がなされるなら、指針も合わせて強化ということになろうが、今改正の「匿名加工情報」の新設は、規制強化ではないとされているので、対応は必ずしも要しないはずである。
したがって、事務局資料3-3「指針見直しの方向性(案)(匿名加工情報・非識別加工情報)」に、「匿名加工情報等は指針の適用対象外とし、指針で上乗せの規制をしないこととしてはどうか。」とある点に賛成である。
続く段落には、学術研究機関の学術研究目的の場合が、個人情報保護法4章の適用除外となって、匿名加工情報に係る義務規定も適用されないからという理由で、「指針で最低限の上乗せの規則を求めてはどうか。」と書かれているが、これも、「匿名加工情報」の新設は規制強化ではないとされているのだから、へたに対応しない方がよいのではないか。改正法施行後に、この指針の適用領域において、「匿名加工情報」の制度がよく用いられるような事態になったら、そのとき指針に盛り込むことを検討するようにすれば足りるのではないだろうか。
*1 文科省の「ライフサイエンス研究における個人情報の取扱い等に関する専門委員会」と、厚労省の「医学研究における個人情報の取扱いの在り方に関する専門委員会」と、経産省の「産業構造審議会商務流通情報分科会バイオ小委員会個人遺伝情報保護ワーキンググループ」の合同会議。
*2 第2波については、2015年3月8日の日記「世界から孤立は瀬戸際で回避」参照。
*3 もっとも、それ以前にそもそも第三者提供自体を実はやっていない(一部を除いて)のではないかという話もある。詳しくは2015年11月21日の日記「CCCはお気の毒と言わざるをえない」参照。
*4 詳細は、日経コンピュータの「Suica乗降履歴データの外部提供で 問われるプライバシー問題——JR東日本に聞く」(2013年7月24日)参照。
*5 この「連結不可能」という用語は日本独自のもので、実際には不可能ではないものまで不可能と呼んでいるところに誤解の種があるように思える。この際、用語を「仮名化」に変更するのであれば、「連結不可能仮名化」とするのではなく、「非連結仮名化」などとしてはどうか。「連結仮名化」(linked pseudonymisation)と「非連結仮名化」(unlinked pseudonymisation)という語が実態に即しているのではないか。
*6 11月のタスクフォースで向井副政府CIOの発言があったのは、個人情報保護委員会が設置される前だったからで、1月以降は、改正法の所掌が個人情報保護委員会に移り、向井副政府CIOの出番はなくなっているようだ。
*7 図1の表の右列は「安全管理措置の一環」として書かれており、その趣旨が、表の直前の文章で、「情報漏洩時のリスクを低減するための安全管理措置として」と説明されているが、ここは、漏洩時のリスクだけではないだろう。ゲノム指針で、匿名化を担当する「個人情報管理者」と研究実施者を分けて、研究実施者に氏名等を持たせないようにしている趣旨は、「情報漏洩時のリスクを低減」だけでなく、研究実施者が研究対象データの本人を認識することがないようにという、プライバシー保護の趣旨もあるはずで、むしろこちらが主ではないだろうか。もちろん、それも安全管理措置の一つということになるが。
*8 異なるのは、情報公開法6条2項の部分開示では、「特定の個人を識別することができることとなる記述等の部分を除く」となっているのに対し、この案2、案3では、「……こととなる記述等の全部又は一部を取り除く」となっているから、ごく一部を取り除くだけで該当してしまう。情報公開法6条2項は、「全部を除く」とは書かれていないが、「……こととなる記述等の部分」というのは、特定の個人を識別することができなくなるまで必要な部分を取り除くという意味だろう。案2、案3の規定ぶりは、そうなっていないので、情報公開法に合わせた方がよいのではないか。
*9 いちおう、「(※1)」のところに書かれている、「希少な疾患などで特定の個人を識別できる場合、データを連結することで特定の個人を識別できる場合など」との記述が、そのことを言っているようにも聞こえるが、「データセットによる照合」の概念を説明するものとしては不完全であるし、「データを連結する」が何と何とのどういう連結を指しているのかが書かれておらず、それを説明したものなのかはっきりしない。
*10 これは、しばしば役所の無謬性が如何の斯うのと言われるところであるが、この場合、単に役所の都合というわけではなく、現行の指針はこの委員会で決めたことであるから、委員会の各委員も間違っていたことになるため、そう簡単に間違っていたとは言い出しづらい。「ここが間違っていると指摘されているので、委員でご検討いただきたい。」と進める方法もあろうが、一部の委員が間違っていないと言い出して面倒なことになるリスクもあるので、そこはうまいこと進めるのも役人のスキルであり、「間違っていた」ことを理由とせず、別の理由から改正を進めてしまうのが得策という面もあるのであろう。
*11 ここで、「元データとの照合なんか要件にしてどうするの?」という疑問の声が出ても不思議でないが、これについては、また稿を改めねばならないが、とりあえず少しだけ申し添えておくと、「防衛庁情報公開請求者リスト事件は10年先行くSuica事案だった(パーソナルデータ温故知新 その2)」に示したように、昔からそうだったということ、また、英国法(Data Protection Act 1998)においても「personal data」の定義で同様に規定されているように、日本だけ独自の考え方というわけではない。
*12 ただ、別所委員発言の内容を、それぞれの委員が正確に理解して肯定しているかは怪しいところがあるように思える。
*13 仮名化しただけでk≧2となる場合は存在する。その代表的な例は、消費者庁が2013年10月に規制改革会議に注文されて示した、「週3日以上ワインを飲んでいるか否か」という二値の属性情報のデータを、対応表を残さずに提供するケースである。
*14 表中の「(※5)」の位置が間違っているようだ。「仮名化」の傍に置くべきものと思われる。
*15 これについては、「現行法の理解(パーソナルデータ保護法制の行方 その2)」の「6. 照合の対象情報の範囲」を参照。
*16 仮名化の元となるデータのことを指す用語が必要で、これにこれまで「個人情報」の語が用いられてきたが、ここを「個人に関する情報」としてはどうか。「個人に関する情報」のうち「個人情報」に該当するものには個人情報保護法の義務がかかる。そのこととは別に、指針では、「個人に関する情報」は「仮名化」処理を施した上で指針のルールに則って利用したり提供するものとすればよいのではないか。
*17 かくいう私も、2014年9月7日の日記「医学系研究倫理指針(案)パブコメ提出意見」では、「意見1「個人情報」の用語定義から「容易に」を削るべき【第2 (20)】」という意見を提出していたが、その後の考察で、「容易に」の有無は、照合の程度問題として捉えるべきではなく、「散在情報的照合性」か「処理情報的照合性」かの違いとして、次の改正で整理し直されるべきだとの考えに至ったので、この意見は取り消したい。
*18 それでいいのかという論点はある。つまり、例えば、記名式Suicaの乗降履歴が、仮名化されただけで、本人同意により第三者提供されたときに、提供先の受領者にとっては非個人情報となるから、だからといって、受領者がさらに第三者提供するときに、無断でやっていいのかという論点がある。また、初めから無記名のSuica乗降履歴が、個人情報保護法で保護されなくてよいのかという論点がある。これは、将来、対象とされるように法改正されるかもしれない。なので、将来の改正に先んじて、医学系研究指針で、受領者においても個人情報として扱うルールにしておくのは良いことだと思うが、それはそれとして、法律上の評価としては、現行法では(来年の改正時も)受領者では非個人情報であることには違いないので、そこを無視するわけにはいかない。
*19 ゲノム指針では、連結可能/不可能匿名化したデータについて、「個人情報に該当しない匿名化された遺伝情報を取り扱う場合には、その取り扱う情報の漏えい、滅失又はき損の防止その他情報の安全管理のため、適切な安全管理措置を講じなければならない。」と規定している。
*20 それ以外に、連結不可能匿名化概念を残す意味があるのかどうか。
*21 他にも、図2の③のところには誤りらしきところがある。「連結可能匿名化」から「手続不要」につなぐ矢印に「対応表を保有しない」との条件が書かれているが、「連結可能匿名化」なのに「対応表を保有しない」というのが、定義に矛盾しており、意味がわからない。
*22 ただし、それは元データを保有する提供元においての話であり、その提供を受けた受領者において、元データが連結可能匿名化データであるときに、受領者において「特定個人を識別できない」という場合を、この図が指しているのであれば、間違いではない。
*23 改正法の「個人識別符号」との混同も避ける必要がある。ゲノム情報を取り扱うときに、個人識別符号に当たるものを取り扱いたいときは、個人識別符号を削除しないと「仮名化」に当たらないというのでは、立ち行かなくなってしまう。
*24 「匿名加工情報」は加工の方法にまで踏み込んでいるのに対し、案1の「匿名化」の非個人情報化は、加工方法について何も言っていないから、その意味では同一のものではない。