2004年09月12日
■ 技術用語「cache」が政治的な言葉として拡大利用される
そもそも「cache」とは
コンピュータ用語としての「cache」は、当初はキャッシュメモリを指すものとして登場した。英単語としての「cache」の本来の意味は、辞書によれば、
cache
—n 《食料や弾薬などの》隠し場, 貯蔵所; 《隠し場の》貯蔵物; 隠してある貴重品; 【電算】 キャッシュ (cache memory).
make (a) cache of… …をたくわえる.
—vt (隠し場に)たくわえる, 隠す; 【電算】 〈データを〉キャッシュに入れる. [F (cacher to hide)]
研究社 リーダーズ英和辞典第2版
とあるように隠れた蓄え場所を指すが、キャッシュメモリはまさにそれである。
下の図のように、キャッシュはメインメモリとCPUの間に配置され、キャッシュがあることによって演算の実行速度が向上するのであるが、キャッシュがあってもなくても演算自体は同じに処理されるというところがミソである。
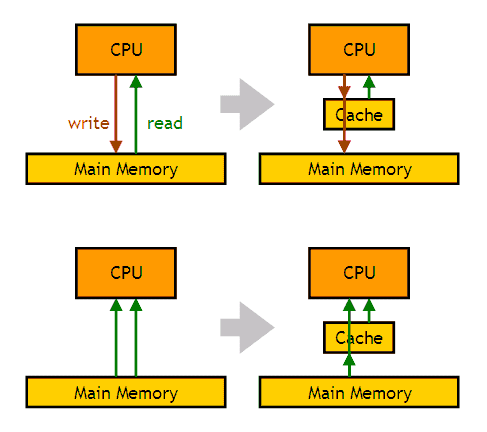
図の上段は、CPUがメインメモリにデータを書き込む(赤の矢印)と、同時にキャッシュメモリにも同じデータを書き込むようになっており、次にCPUが同じアドレスのデータを読み出そう(緑の矢印)としたときには、キャッシュメモリから読み出しが行われる様子を表している。また下段は、CPUが同じアドレスから複数回の読み出しをする際に、1回目はメインメモリから読み出すものの、同時にそれをキャッシュメモリにも保存しておいて、2度目以降はキャッシュメモリから読み出すという様子を表している。
このような仕組みが意味を持つのは、キャッシュメモリの読み出し速度が、メインメモリに比べて高速である場合である。一般に、半導体メモリは、大容量であるほど低速となり、高速にするには高価となるため、低価格で大容量だが低速のメモリをメインメモリとして、高価で小容量だが高速なキャッシュメモリを中間に配置することに意義がある。
このとき、キャッシュメモリの存在を、プログラムからは意識する必要のないように工夫されているところが、「cache」(隠された蓄え場所)と呼ばれる所以である。キャッシュメモリの容量はメインメモリよりも小さいため、全部のデータをキャッシュメモリに入れるわけにはいかない。キャッシュは、それが満杯になったときには、古いものあるいは使用頻度の低いものを破棄して、喫緊に必要なデータに入れ替えるという動作をする。容量が小さいにも関わらず存在意義があるのは、同じアドレスに対するアクセスは連続して発生しやすいという、プログラムの一般的な性質によるところである。
次の図は、1つのメインメモリを複数のCPUで共有して使用する「共有メモリ型マルチプロセッサ」におけるキャッシュメモリの様子を表したものである。同時複数アクセスが可能なメモリは単一アクセスのものに比べて高価・小容量・低速となるため、図のように、CPUに1対1対応するよう配置するのが基本となる。
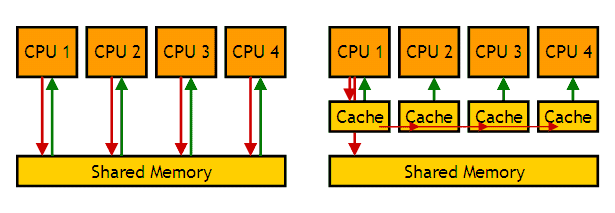
データを読み出すだけならば、CPUが1台の場合と同様にキャッシュは動作すればよいところが、複数台の場合には、データの書き込みが発生したときに特別な措置が必要になる。図の右側は次の状況を表している。
あるメモリアドレスについて、CPU1 〜 CPU4が既に読み出し操作を行っており、データがそれぞれのキャッシュに格納されているとする。ここで、CPU1がそのアドレスに対して書き込み操作を行うと、そのデータはメインメモリには反映されるものの、CPU2 〜 CPU4 が同じアドレスにアクセスしたとき、キャッシュメモリのデータが読まれてしまうのでは、CPU1が書き込んだデータとは異なる古いデータになってしまう(データの一貫性が損なわれる)という問題が生ずる。そこで、この問題を解決するために、CPU1のキャッシュは、書込み操作が行われたとき、他のCPUのキャッシュに対して、同じアドレスに対応するデータを無効化するよう指示したり、データを直接に転送して更新させるといった動作をするよう、回路が付け加えられる。
こうした機構を備えたものを「snooping cache」などと呼び、データの一貫性を確保する課題を「cache coherency」、解決方式を「coherency protocol」などと呼ぶ。これらはここでの本題ではないが、一般に、「cache」と呼ばれる機構には、このようにデータの一貫性が求められていると言える。
Webにおけるcache
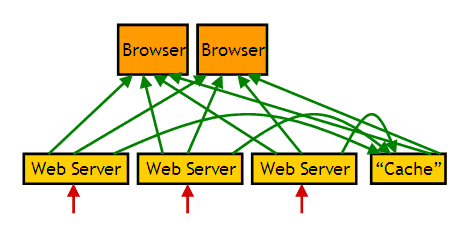
WWWが登場してまもなく、プロキシサーバが発明され、そこにはキャッシュ機構が備えられた。また、Webブラウザ自身もローカルコンピュータ上にキャッシュを持つ。
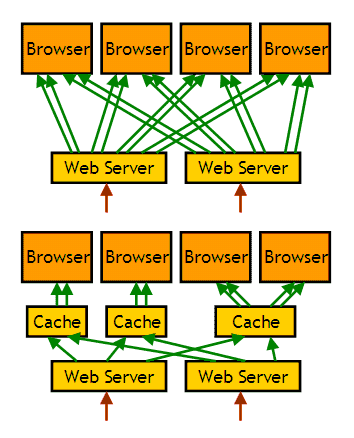
Webにおけるキャッシュの存在意義は、メモリの速度ではなく、ネットワーク的な近さにある。キャッシュ付きのプロキシサーバは、企業や大学などのネットワークの入り口に設置され、組織内のアクセスをプロキシサーバ経由とすることにより、組織から外へのネットワークアクセスの量を減らすことができる。また、Webブラウザのユーザから見れば、組織内の誰かが既にアクセスしたサイトを見に行くと、データは既に組織内のキャッシュに蓄えられているため、素早く画面をロードできるというわけである。
また、ブラウザがローカルコンピュータに持つキャッシュは、一度見た画面を再び表示するときに、再度ネットワークからダウンロードするという無駄を省くために存在している。
Webのキャッシュは、データの書き込み主体が他のユーザである可能性があるという点で、前述のマルチプロセッサの構成に近いが、マルチプロセッサの場合と異なり、書き込みに対する一貫性の確保がさほど重視されない。その理由は、まず、Webブラウザの操作主体が人である(プログラムではなく)からであり、必要があればリロード操作を行えばよいということになる。
しかし、一貫性が全く求められていないわけではない。「今見ている画面は古いのかもしれない」ということがあまりにも気掛かりとなるようでは、あらゆる画面でリロードすることになりかねず、それでは困る。
そこで、HTTPには、「If-Modified-Since」という仕組みが設けられた。これは次のような仕組みである。
あるURLへのアクセスが発生したとき、ブラウザやプロキシサーバのキャッシュが、既にそのURLのデータを蓄積している場合、その蓄積したときの更新時刻(t1)を添えたIf-Modified-Sinceフィールド付きのアクセス要求で、Webサーバにアクセスする。
Webサーバは、If-Modified-Since付きのアクセス要求を受けると、自分が持っているそのURLに対応するファイルの更新時刻(t2)と、指定された時刻(t1)を比較して、前者(t2)の方が新しい場合にだけデータを応答し、新しくないときは「304 Not Modified」応答だけを返してデータ本体は応答しない。
プロキシサーバ(やブラウザ)は、本サーバが304応答を返したときは、キャッシュのデータをブラウザに返し(画面に表示し)、そうでないときは本サーバから送られてくる新しいデータを、ブラウザに転送する(画面に表示する)とともに自身のキャッシュのデータを更新する。
この仕組みにより、ブラウザのユーザは、リロード操作を意識することなくただサイトにアクセスするだけで、常に最新のデータを閲覧できるようになった。
この仕組みが意義を持つのは、転送するデータサイズが大きく、かつ、応答に要求される早さがさほど短くはないためである。CPUのキャッシュメモリの場合は、メモリから数バイトを数ナノ秒で読み出そうというときに、更新時刻の送受信やら時刻比較をしている暇はない。Webで数十キロバイト以上のデータを数ミリ秒程度の時間で表示しようというときには、If-Modified-Sinceの処理をする余裕がある。
ただし、Webのキャッシュにおいて、常にIf-Modified-Sinceによる最新状態の確認処理が行われるとは限らない。一部のプロキシーサーバには、設定された時間内の同一URLへの再アクセスについては、If-Modified-Since付きのアクセスをすることなく、キャッシュデータをブラウザに返すという機能がある。ブラウザも、設定によっては、一定時間確認を省略したり、ブラウザを再起動するまで確認を省略する。
この機能は、ネットワークが遅かった何年か前までは価値あるものであった。キャッシュデータが新しくてサーバへのアクセスが必要でないときに、If-Modified-Sinceは、データ本体の転送を省略するとはいえ、サーバに一旦接続して応答を待つ必要はあり、これに数百ミリ秒以上かかるようでは、画面表示が遅いと感じられる。アイコン画像などは、めったに更新されないのにもかかわらず、毎回If-Modified-Sinceでサーバに確認するのは無駄であるから、省略した方がよいというわけである。
この省略が都合の悪いものとなることもある。自分でWebページをアップロードしたときは、すぐに最新データで画面表示したいはずだが、リロードしても画面が更新されない現象が起きてくる。そういう場合に備えて、「スーパーリロード」と呼ばれる機能(シフトキーやコントロールキーを押しながらリロードボタンを押す)がブラウザには用意された。また、掲示板やショッピングカードなど、リアルタイムに変化がユーザの画面に反映される必要がある場合にも、更新されないキャッシュは邪魔になる。そういうときには、サーバが「Pragma: no-cache」を応答することで、プロキシサーバやブラウザに対して、キャッシュしないよう指示することができるようになっている。
また、HTTP 1.1では、「Cache-Control」によって、サーバ側が各コンテンツに対して、キャッシュでの取り扱いについて様々な細かな指示を出せるようになった。
著作権とcache
1990年代末に、Webのキャッシュが著作権上の問題を含むか否かという議論が活発になった時期があった。キャッシュに蓄積されるデータが著作物の複製にあたるとなると、無断複製ということになり、誰かが違法性を問われかねないという議論である。
これについては、以下の文献を参照するのがよいと耳にしたがまだ入手できていない。
- 塩澤一洋, 「一時的蓄積」 における複製行為の存在と復製物の生成, 法学政治学論究, 1999年11月号, pp.213-?.
「一時的蓄積」について、Webで閲覧できる範囲で調べてみると、2000年5月の東京地裁判決に次の記述があった。
三 争点4(受信チューナーにおける複製権侵害の成否)
1 RAMへのデータ等の蓄積が著作権法上の「複製」に当たるか否かについて
(一)(略)このように、RAMにおけるデータ等の蓄積は、一般に、コンピュータ上での処理作業のためその間に限って行われるものであり、また、RAMにおけるデータ等の保持には通電状態にあることが必要とされ、コンピュータの電源が切れるとRAM内のデータはすべて失われることになる。右のような意味において、RAMにおけるデータ等の蓄積は、一時的・過渡的なものということができ、通電状態になくてもデータ等が失われることのない磁気ディスクやCD-ROMへの格納とは異なった特徴を有するものといえる。(略)
(二)(略)すなわち、著作権法は、著作物の有形的な再製行為については、たとえそれがコピーを一部作成するのみで公の利用を予定しないものであっても、原則として著作者の排他的権利を侵害するものとしているのであり、前記のような著作物の無形的な利用行為の場合にはみられない広範な権利を著作者に認めていることになるが、これは、いったん著作物の有形的な再製物が作成されると、それが将来反復して使用される可能性が生じることになるから、右再製自体が公のものでなくとも、右のように反復して使用される可能性のある再製物の作成自体に対して、予防的に著作者の権利を及ぼすことが相当であるとの判断に基づくものと解される。
そして、右のような複製権に関する著作権法の規定の趣旨からすれば、著作権法上の「複製」、すなわち「有形的な再製」に当たるというためには、将来反復して使用される可能性のある形態の再製物を作成するものであることが必要であると解すべきところ、RAMにおけるデータ等の蓄積は、前記(一)記載のとおり一時的・過渡的な性質を有するものであるから、RAM上の蓄積物が将来反復して使用される可能性のある形態の再製物といえないことは、社会通念に照らし明らかというべきであり、したがって、RAMにおけるデータ等の蓄積は、著作権法上の「複製」には当たらないものといえる。
これは、デジタル放送の再生装置において、装置のシステム構成上の都合として、音楽のデジタルデータが、一時的に揮発性メモリに格納されることについて、それが著作物の複製にあたるかが争われたケースである。
では、キャッシュはどうだろうか。キャッシュは、2度目以降の読み出しを高速化することに目的があるのだから、「将来反復して使用される」ことを意図したものと言えるので、上の裁判例が対象としたものとは異なる。
また、2000年11月に公表された著作権審議会国際小委員会報告書に次の記述があった。
(3)「一時的蓄積」の取り扱いの検討
○ デジタル化、ネットワーク化の進展に伴い、通信機器における蓄積、コンピュータのメモリー上における蓄積、キャッシュサーバーなどにおける蓄積など、瞬間的かつ過渡的なものを含め、プログラムの著作物及びその他の著作物に関する電子データの「一時的蓄積」の扱いが重要課題となっている。
○ 「一時的蓄積」に関して、我が国では1995年(平成7年)2月の著作権審議会マルチメディア小委員会ワーキング・グループ検討経過報告書においては、「一時的蓄積」のうち「プログラムの実行に伴うコンピュータの内部記憶装置への蓄積は、瞬間的かつ過渡的なものであって、『複製』には該当しないとの解釈が一般的である(著作権審議会第2(1973年(昭和48年)6月)・第6(1984年(昭和59年)1月)小委員会報告書)」としている。また、1985年(昭和60年)9月の著作権審議会第7小委員会報告書においては、データベースの場合、「内部記憶装置と外部記憶装置を区別せず、インプットした情報を直ちに処理して消去する場合は別として、コンピュータの記憶装置への蓄積は複製に該当すると考えられる」としている。
○ 他方、1996年(平成8年)12月のWIPO外交会議において採択された「WIPO著作権条約に関する合意声明」においては、「保護を受ける著作物をデジタル形式により電子的媒体に蓄積することは、ベルヌ条約第9条が意味する複製に当たると解するものとする。」としつつ、WIPO事務局より、瞬間的・技術的な蓄積についての議論の際に、「蓄積」については各国に異なる解釈の可能性がある旨指摘されている。
○ 「一時的蓄積」に関しては、各国間で、権利の対象外とする範囲について様々な考え方があり、技術的背景の変化及び国際的な議論の動向を踏まえつつ、その扱いについても検討する必要があると考えられる。
<施策の進め方>
○ プログラムの著作物及びその他の著作物に関する電子データの「一時的蓄積」の扱いについて、著作権審議会などにおいて検討する。
著作権審議会国際小委員会報告書 〜情報技術(IT)、電子商取引の進展に対応した国際著作権政策の在り方〜, 2000年11月
「キャッシュサーバーなどにおける蓄積など」という語句の直後に、「瞬間的かつ過渡的なもの」という表現が出てきているが、キャッシュは瞬間的とは言えないので、これには違和感がある。
このままの法律ではおそらく、Webのキャッシュは著作物の複製にあたるということになってしまうと思うが、技術者の心情からすれば、キャッシュの仕組みが著作権法によって規制されることには、直感的に強い抵抗を感じるのが一般的であろう。
それを避けるために、技術面からなしておくべきことは、キャッシュという用語が指す技術的特性の範囲を明確化することである。
蓄積機構がcacheと呼べる条件
最初に整理したように、CPUがメインメモリにアクセスするときのキャッシュメモリにせよ、Webにおけるキャッシュにせよ、データの一貫性管理が要求されているという特徴がある。それはすなわち、キャッシュがあってもなくてもシステムは同等に動作するということが要件となっていることを意味する。つまり、アクセス元からアクセス先を見るとき、キャッシュが透過的であることが要件である。cacheという単語の本来の意味が「隠れた蓄え場所」であることに附合する。
キャッシュの最も狭い定義を、次の機能を備えていなくてはならないとすることができる。
(1) キャッシュへのアクセスがあったら、オリジナルのデータが更新されているときは、キャッシュ上のデータも更新したうえで、データを応答する。
この条件を少しだけ緩めた次に狭い定義を、以下のようにすることができる。
(2) キャッシュへのアクセスが、一定の時間内あるいは条件を満たすタイミングであった場合は、そのままキャッシュ内のデータを応答し、それ以外の場合では、オリジナルのデータが更新されているときは、キャッシュ上のデータも更新したうえで、データを応答する。なお、一定の時間は十分に短い(たとえばWebキャッシュの場合10分など)必要があるし、条件を満たすタイミングはシステムの用途に応じて妥当でなくてはならない。
オリジナルのデータの更新状況は、If-Modified-Sinceのような方法で随時確認する方法や、マルチプロセッサにおけるsnooping cacheのように、データを更新した側からの指示によって他を更新もしくは無効化することで、常に更新が保証されるようにしておく方法がある。
「一定の時間内あるいは条件を満たすタイミング」とは、Webのキャッシュのように、一定時間オリジナルデータの更新を確認しない方式における一定時間や、共有メモリ型マルチプロセッサ向けのキャッシュや分散共有メモリなどでの、同期機構と連携した一貫性プロトコルにおける、同期のタイミングなどが該当する。
オリジナルデータが消滅することのあるシステム(Webなどが該当)では、オリジナルデータが消滅すれば、キャッシュデータも消滅するようにすることが、一貫性制御がなされていると言える要件となろう。
著作権の観点から見たとき、このような特性を備えたキャッシュの存在に、どのような問題が生ずるだろうか。
(1)の定義のキャッシュであれば、ユーザから見える著作物は、オリジナルと常に同じように見えるのであるから、実質上の問題が生じないと言える。
(2)の定義のキャッシュの場合は、オリジナルデータが更新されても、いくらかの時間が経過しないと更新が反映されないという不都合が生ずる。これはたいした問題とならないことも多いが、問題をもたらすこともある。
たとえば、ユーザ認証を経て特定のユーザにだけ閲覧させたはずのデータが、キャッシュに残っていたために、後に別のユーザが同じキャッシュ経由でアクセスしたときにも、データを閲覧させる結果になってしまった場合が該当する。
しかしこれは、HTTPの Cache-Control ないし Pragma: no-cache 機能を使うことで、コンテンツ作成者側が防ぐことができる。
1990年代からの議論を経て、現在では、(HTTPの仕様を無視して動作するキャッシュシステムを除けば)Webのキャッシュは著作権上妥当なものとしてほとんどの人がとらえていると考えられる。
Googleが「cache」と自称するもの
それに対し、Googleなどが始めて、後にYahooやgooなども採用するようになった、Web検索サイトにおける「キャッシュ」サービスはどうだろうか。
まず、アクセス元(ユーザ)側から見て、この「キャッシュ」は透過的でない。その存在は目に見えて意識的に使われるものであって、「隠れた蓄え場所」には全くなっていない。
システムアーキテクチャから見ても、伝統的なキャッシュとは異なり、アクセス元からの要求が来る前から、検索サイトが自らオリジナルデータを収集して「キャッシュ」に蓄えている。必要に応じてではなく、全部を蓄えようとしている。
上に整理した(2)のキャッシュの定義からすれば、「一定時間」が一週間を超える場合もあるような長期間となっていて、キャッシュと呼べるには限度を超えていると見ることもできる。
Googleは、この機能の存在意義を次のように説明している。
キャッシュ
このリンクをクリックすると、インデックス付けの時点で保存されたページのコンテンツが表示されます。Googleでは該当ページのサーバがダウンした場合でも、検索が行えるよう多数のウェブページをキャッシュに格納しています。キャッシュ済みバージョンでもキーワードがハイライトされます。
なるほど、該当ページのサーバが一時的にダウンしていても閲覧できるようにというのは、便利だ。だが、目的は本当にそれだけなのだろうか。
Googleの「キャッシュ」と称すものは、伝統的な本来のキャッシュシステムにより近づけることはできるはずである。具体的には次のようにすることが考えられる。
ユーザが「キャッシュ」のリンクをクリックしたとき、Googleから当該URLのオリジナルサイトへデータの更新状況の確認アクセスを行い、更新されているならば、更新されたデータをブラウザに応答するようにする。
「そんなことを実現するにはコストがかかりすぎる」という声が聞こえてきそうだが、はたしてどうだろうか。現在の「キャッシュ」の更新が一週間以上かかることもあるのは、世界中のすべてのWebサイトを網羅的に巡回して更新しているためである。これをたとえば1時間以内にすべてについて行うのは不可能であろう。だが、それは、閲覧されていないキャッシュも含めて更新しようとするからだ。
ユーザが「キャッシュ」リンクをクリックしたときにだけ更新確認する仕組みで発生する更新確認アクセスの数は、ロボットが全世界を巡回するときのアクセス数よりずっと小さくできるはずである。「キャッシュ」へのアクセス数が、Google全体のアクセス数の何割かということもあるが、すべてのアクセスで更新確認をする必要もない。たとえば、一人目が「キャッシュ」にアクセスに来た時点で更新確認をし、それから10分間は同じURLの「キャッシュ」にアクセスが来ても更新確認をしないという動作をするのは、十分に妥当かつ効果的だと考えられる。
また、一人がたまたま「キャッシュ」を閲覧しただけでは更新確認しないという方法も考えられる。たとえば10人ほどが短時間に連続して異なるIPアドレスからアクセスしてきたら、そのページのキャッシュが何らかの原因で注目を浴びている(たいていは良からぬことが起きている)と判断して、更新確認するようにするといった具合だ。
こうした、伝統的なキャッシュとして振舞うための方策は考えられるが、採用されていない理由は、自分のコンテンツを早く更新させるために、意図的にキャッシュへのアクセスを発生させる輩が現れた場合に、それが多くのサイトについて常態化してしまうと、その処理のコストが無視できなくなるほど大きくなりかねないということがあるためなのかもしれない。
それに対する対策は何か考えられるかもしれないが、そこまでのコストをかけてまで、伝統的なキャッシュの動作に近づける必然性があるとまでは認識されていないのだろう。
こうした「キャッシュ」の仕組みは、やはりこれまでにも何度か著作権上の問題があるとして物議を醸してきている。
- 米グーグルのキャッシュ機能は著作権侵害?, CNET News, 2003年7月10日
- 検索エンジンのキャッシュは著作権侵害か?, スラッシュドットジャパン, 2002年3月18日
また、これは著作権上の問題だけではなく、プライバシー漏洩事故発生時の被害拡大をもたらすという面も持ち合わせている。
- Googleキャッシュで鳥取県個人情報流出の2次被害, スラッシュドットジャパン, 2003年8月11日
Googleに「キャッシュ」されることを避けるには、HTMLコンテンツに METAタグで次のように書けばよいと、Googleは説明している。
サイトのコンテンツをロボットがアーカイブしないようにするには、以下の NOARCHIVE メタ タグを使用します。 このタブをドキュメントの
セクションに次のように挿入します。<META NAME="ROBOTS" CONTENT="NOARCHIVE">
これには不満の声も出ている。コンテンツ提供者が自らのコンテンツのキャッシュ方法を指示するというのは、先に述べた HTTP/1.1の「Cache-Control」にも共通しているが、両者はやや性質が異なっている。
Cache-Controlを必要とするような状況は、技術力をもってサイト構築が行われている場合(ログインユーザごとに異なるコンテンツを見せる場合など)がほとんどであるように思える。静的なコンテンツを提供している場合には、透過的なキャッシュが大きな問題を起こすことは少ないと言える。そのため、「キャッシュされるのが困るならばCache-Controlで制御せよ」という言い分はある程度通るのであるが、それに対し、Googleに「キャッシュ」されて困るのは、そのような技術力を持たない一般の人たちであることが多い。なぜなら、Googleの「キャッシュ」は透過的でないため、静的なコンテンツでも小さくない問題が十分に生じ得るからだ。
Googleは、緊急時には次の方法で「キャッシュ」を削除できると説明している。
注意: 緊急を要し、Google が次回サイトをクロールするまで待てない場合は、自動 URL 削除システムをご使用ください。このプロセスが機能するためには、Web マスターがまず適切なメタ タグをページの HTML コードに挿入する必要があります。
これはようするに、コンテンツの提供者自身がまず METAタグをコンテンツに挿入して、「キャッシュ」して欲しくないことの意思表示をした後に、Googleに対して申請を行うと、METAタグが確認されて「キャッシュ」が消去されるという仕組みだ。
ここで疑問に思うのは、どうして削除しかしてくれないのかということだ。つまり、申請すると、METAタグとは関係なしに、最新の内容にアップデートしてくれるというだけでも、トラブルは解決するはずである。「キャッシュ」とは本来そのように動作するもののはずだ。Webのキャッシュで言う、スーパーリロードのようなことができるべきである。それが行われていないのは、やはり、不当に申請を乱発する輩が現れることを避けるためなのだろうか。
このようなことを書いたが、これは、私自身が、Googleの「キャッシュ」は廃止するべきであるとか、著作権法違反であると主張したいわけではない。Googleの「キャッシュ」や、archive.orgのアーカイブを便利に使うこともある。
ここで言いたいのは、キャッシュでないものをあえて「キャッシュ」と呼ぶことのインチキ臭さ、不誠実さだ。Google自身が、
サイトのコンテンツをロボットがアーカイブしないようにするには、以下の NOARCHIVE メタ タグを使用します。
と言っているように、これはキャッシュではなく、アーカイブである。一時的なアーカイブであろう。
キャッシュでないものを「キャッシュ」と呼ぶ意図は、著作権法違反と指摘される可能性を意識してのものではないか。
つまり、狭い定義の「キャッシュ」であれば、たとえ法的にその位置づけが明確になっていないにせよ、多くの人達が妥当だと考えているのに便乗して、狭い定義の「キャッシュ」を逸脱した仕組みまで「キャッシュ」と自称することによって、素人の目を混乱させて、同様に妥当であるかのように見せかけている。
もしGoogleの「キャッシュ」が著作権法上問題だと問われる事態になれば、「これが違法だというのなら、プロキシサーバや、Webブラウザのキャッシュまで違法ということになってしまう」という馬鹿な詭弁が出てくるに違いない。
妥当な利用まで規制されかねないような、紛らわしい用語の使い方は迷惑である。少なくとも技術者がすることではない。
Winnyの「cache」
そしてWinnyの「キャッシュ」である。
Winnyにおいて、無断で公衆送信可能化すると著作権侵害になるコンテンツが大量に流通しているにもかかわらず、逮捕者が多数は出ない原因は、データを送信可能化しているといっても、それが「中継」であるのか、Upフォルダでの一次配布元であるかの区別が、外部からは判別できないようになっているところにある。
そして、「中継」する行為が違法でないとする立場からは、「もしWinnyの中継が違法ということになったら、ISPのルータのパケット中継も違法ということになってしまうじゃないか」という主張が出てくる。
ISPのルータでは、データは通過するだけである。瞬間的にメモリ上に蓄えられることになるだろうが、これはまさに法的にも通説となっている「一時的蓄積」に該当するであろう。
それに対しWinnyの場合では、多くのケースで、実際の中継は行われず、「キャッシュ」からデータが出ていく形になる。
ファイルを要求したノードA が直接に接続したノードB が中継をしていたとしても、その中継先のノードC がさらに中継している確率は小さく(ゼロに?)設定されており、それがUpフォルダでの一次提供元でないのなら、ノードCは「キャッシュ」からデータを送信していることになる。
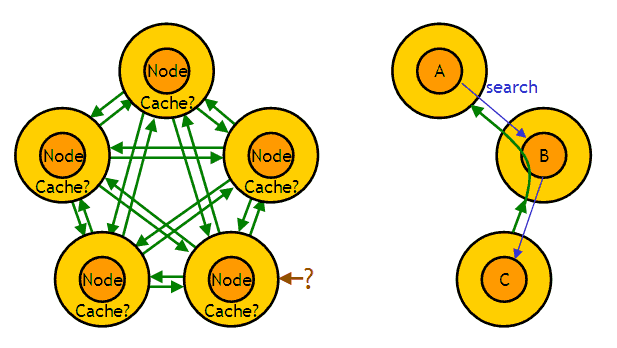
あるファイルがUpフォルダに入れられている間は、一次提供元をrootとしたツリー構成が成立すると見ることもでき、その時点では「キャッシュ」が本来の意味でのキャッシュの構成になっていると言えなくもない。しかし、Upフォルダのデータはすぐに消されることを元から想定しているうえ、Winnyの「キャッシュ」にはデータの更新という機能がない(更新されたデータは別のファイルとして扱われる)。
- Winnyの「キャッシュ」は、「あってもなくても同等に動作する」という性質を備えていない
- Winnyの「キャッシュ」には、一貫性制御が存在しない
ここでも技術用語「cache」が政治的に拡大解釈使用されている様子が見られる。